
Efficiera Models
Quantization is one of the methods to make AI models lighter. We can solve the problems faced by edge AI with our ”extremely low-bit quantization technology,” in which models are quantized to the extreme limit of 1 bit.
High-performance AI models for edge devices
Limited computing resources, power consumption, and memory limitations, are major issues in running AI on edge devices.
LeapMind believes that solving software problems is as important as hardware problems, and attempts to solve these major challenges by rewriting the AI computation method itself.
Practical AI models consist of more ( or deeper) convolutional layers, which results in a large amount of overall computation. Performing this computation using floating-point numbers without quantization requires a large number of floating-point units (FPUs) to operate at high operating frequencies, which makes it difficult to make AI models work practically on edge devices.
Using extremely low-bit quantization technology, bitwise operations can be used instead of FPUs which require large circuit areas. It dramatically reduces circuit size, RAM to hold weight and activation, and bandwidth to access the main memory.
LeapMind offers a range of extremely low-bit quantized AI models that support a wide variety of tasks in edge devices.
FEATURES
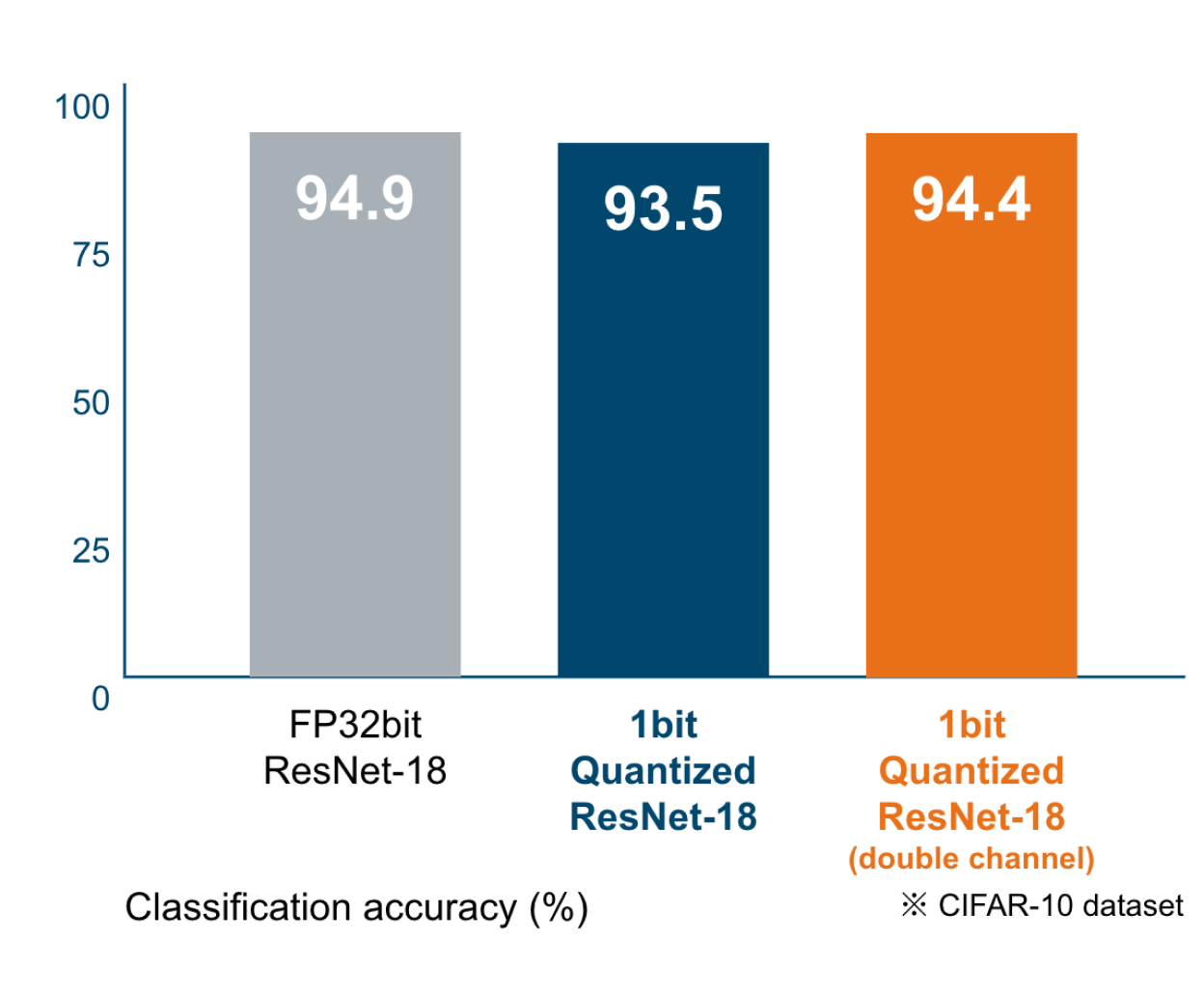
Minimizing Accuracy Degradation
LeapMind uses several methods to prevent accuracy degradation. Typical examples are quantization aware training, doubling channels, and pixel embedding.
Quantization aware training is a very important technique for extremely low-bit count quantization. Networks with extremely low quantization bit counts can achieve equivalent accuracy with twice the number of channels (doubling channels).
Although the input data to the first convolutional layer is considered difficult to quantize, we have succeeded in quantizing the first convolutional layer using our unique technology called pixel embedding.
Real-time image processing with high-resolution input
The amount of computation required for high-resolution input increases, and implementing real-time processing on edge devices with Full Precision has been considered impossible due to the amount of computation, memory, and bandwidth required.
However, this can be achieved by compressing the model size and implementing it in consideration of memory bandwidth.
Realtime Image Recognition with Multi Channel/High-Resolution Input
In image recognition tasks such as object detection, there is a trade-off between recognition accuracy and model size. Efficiera models can achieve the following performance for even the most demanding applications. (cf. MobileNetV2 SSD-Lite: mAP(0.5): 0.686)
• mAP(0.5): 69.8
• 30.6GOPS/frame
• FPS (operating frequency 500MHz): 401


TECHNOLOGY

Audio and subtitles only in Japanese
Extremely low-bit quantization
Quantizing deep learning models makes them lighter and significantly reduces their space and computational complexity. Yet performance degradation can be he kept to a minimum.
Specifically, we achieve weight savings by replacing the parameters in an inference model with 1 or 2 bits instead of the usual single-precision floating-point number (32 bits).
The limit of quantization without performance degradation is generally believed to be 8 bits, but LeapMind has succeeded in achieving negligible performance degradation even with a combination of 1-bit weight (weight factor) and 2-bit activation (input), which is much less than 8 bits.
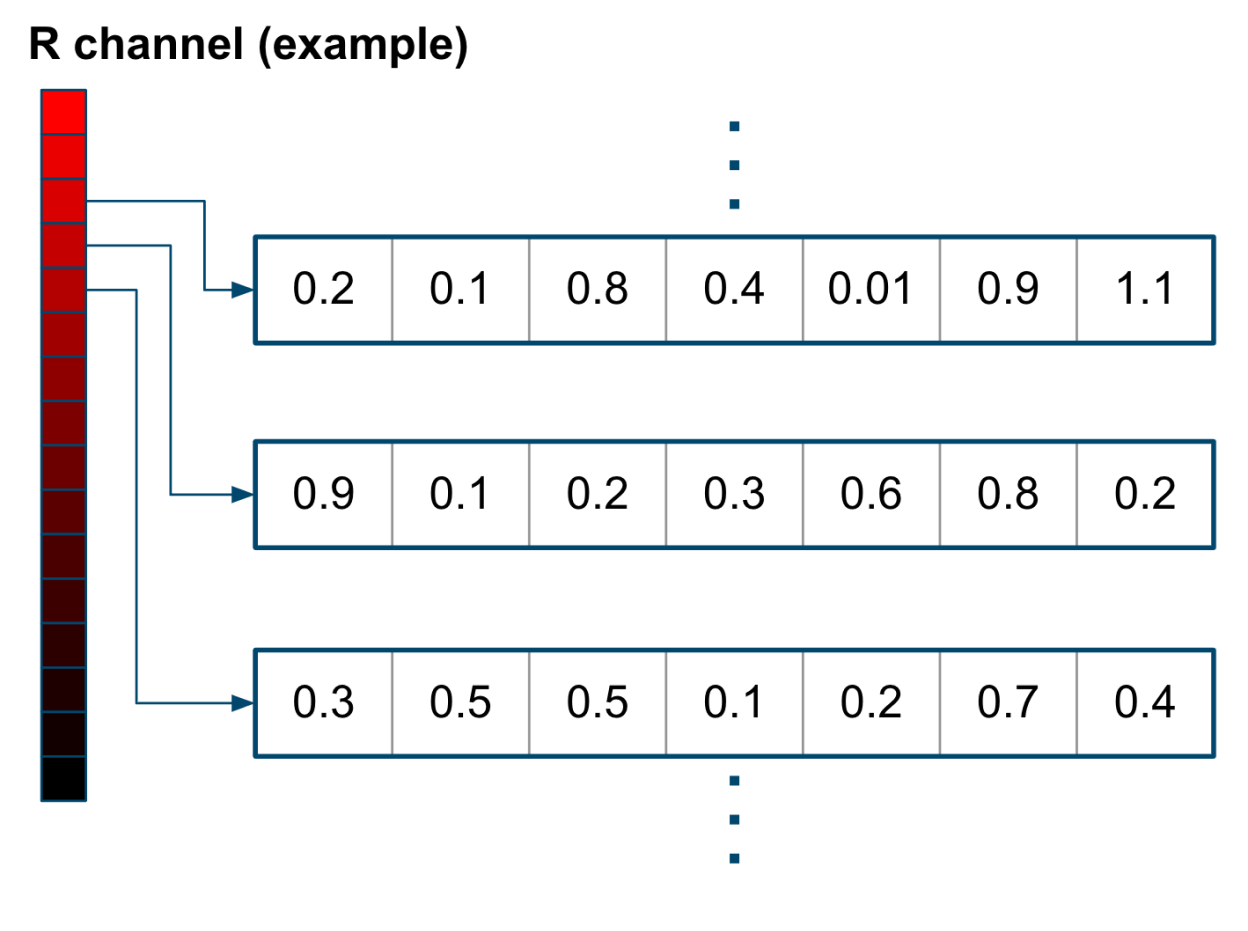
Pixel Embedding (Convolutional Arithmetic)
LeapMind uses its proprietary ”Pixel Embedding (convolutional operations)” technology for the quantization of the first layer of neural networks, which has a large impact on inference accuracy, as a method of converting input data to minimize accuracy degradation.
While the first convolution operation on the input data typically uses floating-point or integer operations with more bits, LeapMind encodes the input data into multiple channels of 2-bit data. This allows the use of extremely low-bit quantization techniques from the first convolution layer.
APPLICATIONS
IMAGE PROCESSING
Image Noise Reduction
AI technology that reduces high-ISO noise caused by low-light shooting to achieve high image quality
Video Noise Reduction
AI technology to achieve high image resolution in real-time for video recording where long-second exposures are difficult to use
Super Resolution
AI technology to enhance low-resolution digital images while preserving sharpness
Deblurring
AI technology to reduce blur caused by camera shaking or shooting moving subjects
Deraining
AI technology to remove water drops on the surface of the camera lens from the image after shooting
IMAGE RECOGNITION
Object Detection
AI technology to detect where people, vehicles, and other objects are located in an image
Segmentation
AI technology to divide colors by object areas
Pose Estimation
AI technology to estimate the position of human joints and major points (neck, shoulders, elbows, wrists, ankles, etc.) and their connections
Classification
AI technology to recognize objects in images and classify them
Anomaly Detection
Detects anomalies by training only normal images