
Efficiera IP
As an AI accelerator, its outstanding performance in PPA(Power, Performance, and Area) enables practical AI models to run on edge devices.
Superior power and area efficiency: Enabling AI devices to be more power-saving and cost-efficient
In order to operate practical AI, the hardware computing performance and power consumption have significant impacts due to its enormous amount of calculations, and it is difficult to practically operate AI on edge devices unless semiconductor performance dramatically evolves.
In response to this challenge, we have developed an ultra-low power AI accelerator IP specialized for CNN (Convolutional Neural Network) inference processing that achieves 107.8 TOPS/W* of computing power, thereby contributing to the practical use of AI. We also have completed successful SoC development at TSMC 28nm and 12nm using this IP**.
Additionally, ISO 9001 certification has also been granted to meet quality requirements.
Our strength is to maximize the power and area efficiency of convolution (convolution operation), which accounts for most of the inference processing, by minimizing the quantization bit to 1-2 bits using our ”Extremely low bit quantization” technology. There is no need to use the latest semiconductor manufacturing process or special cell libraries.
By using Efficiera, deep learning functions can be embedded in a variety of edge devices, including consumer devices such as smartphones and digital cameras, automotive, industrial equipment, construction machinery, surveillance cameras, and broadcasting equipment, where all these devices were deemed difficult to incorporate deep learning due to technical constraints caused by power, heat dissipation and cost.
*TOPS/W: Tera operations per second per watt.
*Estimated values based on logic synthesis results using Cadence Genus Synthesis Solution. (Operating frequency:533Mhz, Process:7nm, as of July 2023)
** https://www.nedo.go.jp/news/press/AA5_101526.html, https://www.nedo.go.jp/news/press/AA5_101614.html
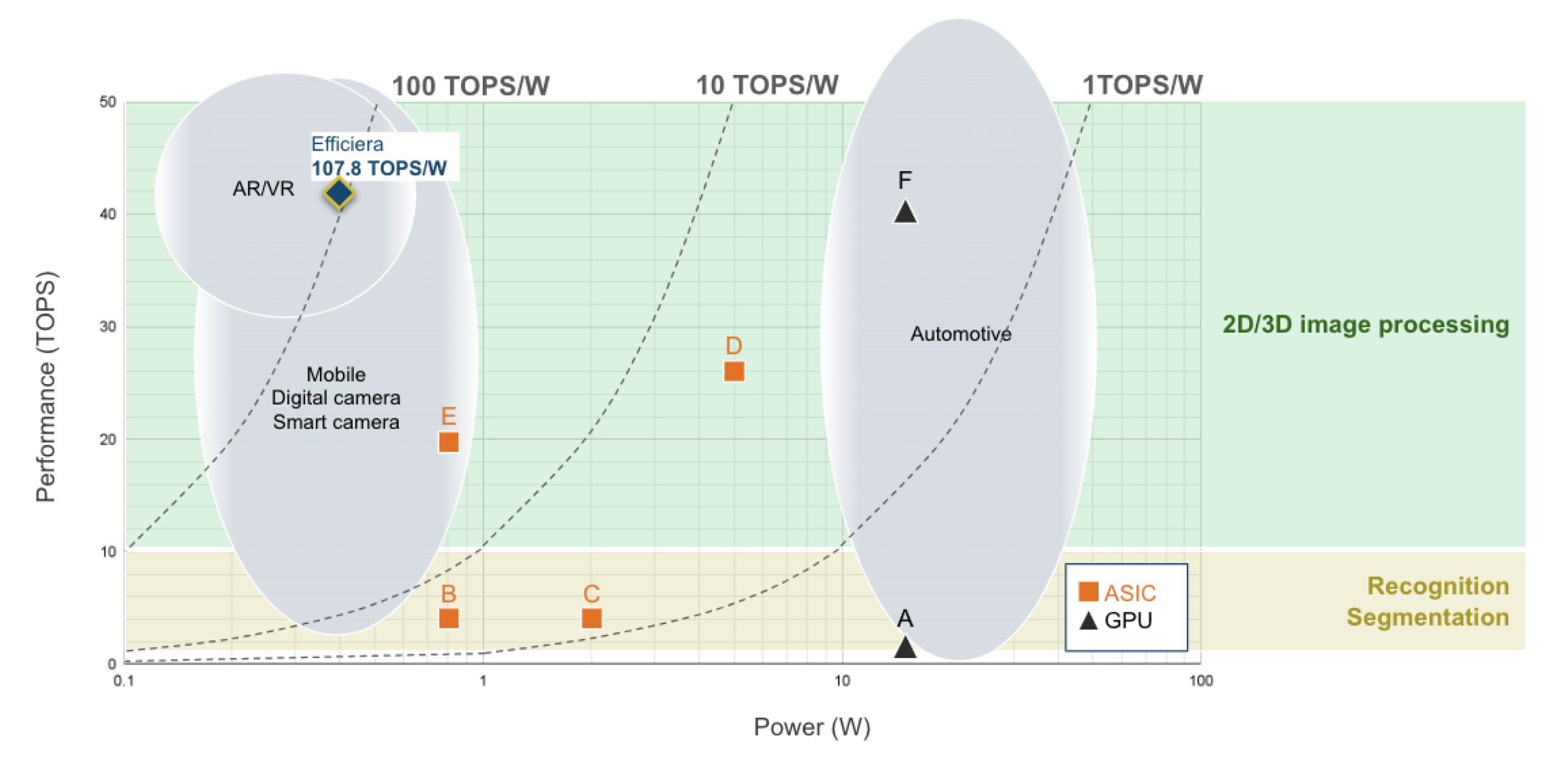
(AI task and required performance)
FEATURES

Superior power performance for AI processing on edge devices
LeapMind's proprietary AI accelerator, Efficiera, achieves power performance of up to 107.8 TOPS/W* and can process high-quality images and video in real-time on edge devices.
*Terra operations per second per watt
Area-saving semiconductor circuits specialized for CNN (Convolutional Neural Networks)
Convolutional neural nets offer the flexibility to operate in any network task and, in their smallest configuration, have a very small circuit size of 0.245㎟, thus eliminating the need for advanced manufacturing techniques and significantly reducing power consumption.
Using the low-power 6-track cell library, 533 MHz operation is achieved by using only STV cells. The operating frequency can be further increased to 1066 MHz.
Performance scalability of Efficiera®️
Efficiera is provided as synthesizable RTL.
By adjusting computing performance through channel configuration selection and CPU occupancy, the system can handle the required hardware performance range for real-time (around 60 FPS) processing of image recognition tasks such as object detection as well as image processing tasks such as image quality improvement.
FUNCTIONS
Hardware Features
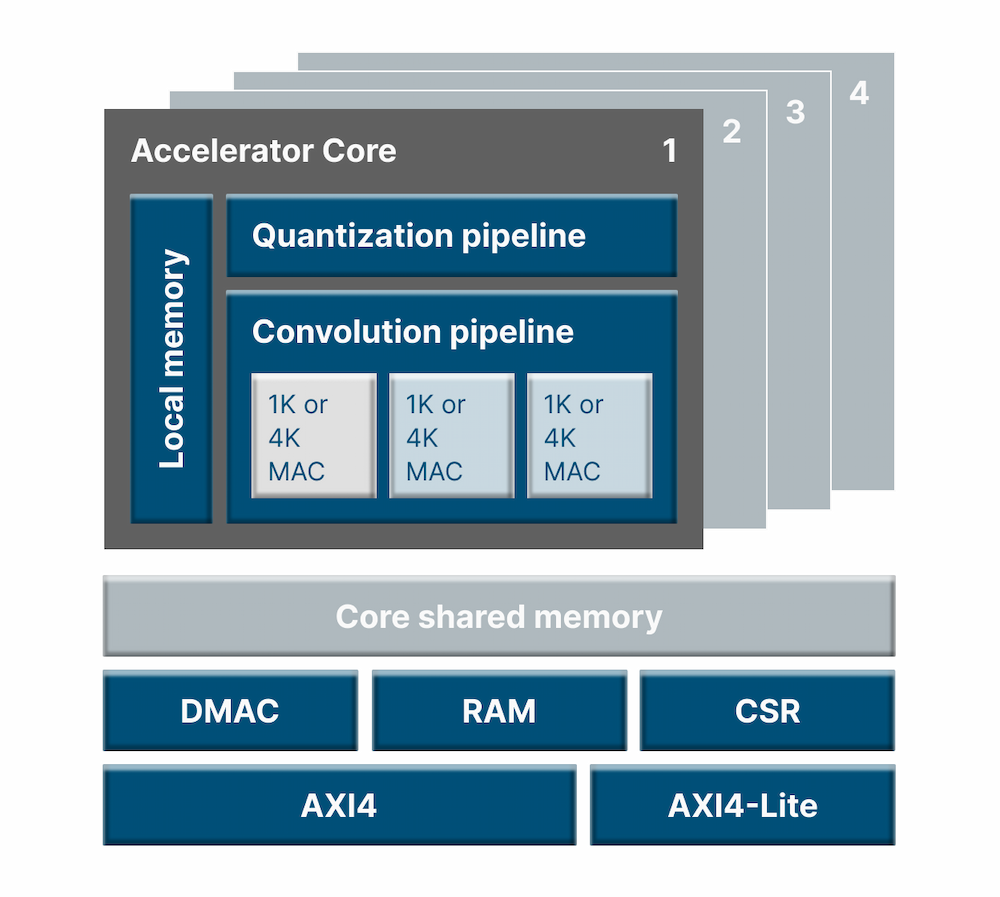
Multiplexed MAC arrays + multi-core for high performance scalability
High speed-up by hardware execution of Skip connection(*1) and Pixel Embedding(*2) in addition to convolution and quantization
*1 Skip connection is an operation method often used in CNN (Convolutional Neural Network) with a large number of layers, which enables forward and backward propagation between distant layers by bypassing a path that skips N layers in the middle of a layer and connecting it to the next layer.
*2 Pixel embedding is LeapMind's proprietary technology (patent number:), a method similar to word embedding used in natural language processing, in which a random value is assigned to each pixel value, a vector is input to the network instead of pixel values, and the input data is quantized A technique that converts the first and last layers to 2-bit by using
Integration into SoC
AMBA AXI Interface
Continued use of AMBA AXI for external interface, with the same interface as before when viewed as a black box, allowing easy migration from existing designs
Single clock domain design
Operating Frequency
1GHz at 12nm, 800MHz at 28nm
Applicability can be extended to 256 GOP/s with FPGA@125MHz and 104 TOP/s with 12nm process technology.
PRODUCT LINEUP
Efficiera-B Configuration
Ultra-efficient IP for image recognition applications. Primarily, it is capable of performing ultra-fast image recognition in demanding environments with high latency requirements due to multi-channel input, at low power consumption and low memory bandwidth.
Efficiera-E Configuration
This is an ultra-efficient IP for image processing applications. It can perform tasks that were previously unfeasible, mainly in scenarios that require real-time and highly accurate processing, such as noise reduction during night shooting, upscaling to 8K, and image stabilization.