September 21, 2022
Summer Internship 2022 – Nishio – Go beyond the accuracy of the Float model with Binary Neural Networks.

こんにちは。LeapMind インターン運営担当です。 本日は、2022年サマーインターンに参加されたインターン生の成果発表について記事にまとめたいと思います。
My summer internship experience at LeapMind
Hello, my name is Nishio and I participated in the 2022 summer internship program. For a little less than two months, I worked with the NDK team on an experiment to reproduce a paper of binary neural networks. The paper I replicated is “Binary Neural Networks as a general-propose compute paradigm for on-device computer vision” [1]. The “BiNealNet” proposed in this paper is claimed to outperform 8-bit quantization methods in the speed-vs-accuracy tradeoff for classification, detection, segmentation, super-resolution, and matching.
Implementation Overview
BiNealNet is one of the binary neural networks that achieves high accuracy and computational efficiency for various tasks by using the following two techniques:
- Binarize a ResNet block by enlarging its channels.
- Injecting auxiliary parameters in binaryconvolution and binary activation.
Binarizing ResNet blocks allows for easy extension to various tasks, and the larger number of output channels in the block increases the capacity of the network. In addition, auxiliary parameters also improved the expressiveness of the network.
Binarization of ResNet blocks is realized by two methods: binarization of convolution weight parameters and binarization of activation.
Weight parameters of convolution are binarized by Wb = Sign ( Tanh( Wf ) ) Wf Wb Where Wb is the value of the binarized weight and Wf is the full precision weight, and are arbitrary parameters. Sign function calculated the gradient using STE [2]. is a channel-wise parameter. is implemented so that the shape could be selected from one-, two-, or four-dimensional tensors according to the paper.
Activation is binarized by Ab = Sign ( Htanh( PReLU( Af + b0 ) + b1 ) ) Af = Ab where Ab is the value of the binarized activation and Af is the full precision activation, , b0, b1 are channel-wise, and is a scalar arbitrary parameter. Htanh backpropagation was implemented as follows [3]:
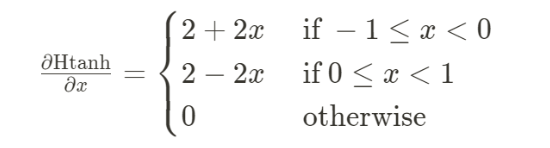
This implementation reduces the mismatch in the gradient of the backpropagation of the sign function.
Results of Reproduction Experiments with CIFAR10
The implemented BiNealNet was validated using CIFAR10, a typical classification task. The maximum number of training epochs was set to 400 and the batch size to 128, starting with a learning rate of 0.1, and then decaying using the learning rate scheduler with SGDR [4].
Validated ResNet accuracy with full precision activation and weights as a baseline, yielding 0.9479 as validation prediction accuracy. Verified whether the prediction accuracy is equivalent to a full precision network without degradation when weights or activation are binarized. Thereafter, when binarizing weights and activations, the number of channels was set to 1.5 times the original ResNet, following the paper [1].
First, only the weight parameters were binarized to obtain a validation prediction accuracy of 0.9485. When binarizing the weights, the weight parameters of the first convolution were not binarized. (The same applies thereafter.) We then binarized the activation and obtained a validation prediction accuracy of 0.922. Finally, when both the weight parameters and activation were binarized, we obtained 0.911 as the validation prediction accuracy.
Full precision (baseline) 0.9479 Binarize Weight 0.9485 Binarize Activation 0.922 Binarize Weight & Binarize Activation 0.9112
Binarization of activation caused degradation of prediction accuracy and did not produce the results as in the paper.
For further verification, we changed the following three points.
- Change the kernel size of the convolution layer of downsampling from 1 to 3.
- Clip the negative slope of PReLU so that it is not less than 0.
- Move scaling parameters of and to after the convolution.
- The initial earning rate of new auxiliary parameters is reduced by a factor of 10.
In the original ResNet, the kernel size of the downsampling layer is 1, but it is known empirically that a kernel size of 1 is inaccurate when the convolution weights are binarized.
Kernel size of downsampling = 1 0.9112 Kernel size of downsampling = 3 0.9214
Based on this result, the kernel size of the downsampling layer was subsequently set to 3.
Next, the negative slope of PReLU was verified by replacing it with a function that was clipped so that the negative slope of PReLU was not less than zero. This was because BiNealNet implicitly assumed that the value of the negative slope of PReLU was non-negative.
Normal PReLU function 0.9214 Clipped PReLU function 0.9235
Thereafter, the clipped PReLU was used in the activation binarization.
Thirdly, the position of the scaling factor was verified. The scaling factors for the activation and convolution weights were moved after the convolution operation. This makes all the inputs to the convolution operation 1bit. Accuracy was significantly reduced.
Scaling before conv 0.9235 Scaling after conv 0.9076
Finally, we considered reducing the learning rate of the added arbitrary parameter to make the change smaller.
Same initial LR (0.1) 0.9235 Lower initial LR for new parameters (0.01) 0.9102
Summary and Future Outlook
The BiNealNet paper was ambiguous in many of its descriptions, which was a barrier to validation. We attempted to replicate the paper by experimenting with a variety of patterns, but ultimately ended up with a validation prediction accuracy that was 0.0244 points lower than the full precision network for the CIFAR10 dataset. Within this summer internship, I also worked on an experiment in object detection using BiNealNet and MSCOCO dataset, but I will not go into details.
BiNealNet is claimed to have produced accuracy comparable to 8-bit models in segmentation, super-resolution, and matching, so we would like to verify its effectiveness for tasks other than classification and object detection.
LeapMind is a great place to work!
I worked at LeapMind for less than two months as an intern and had a very enjoyable and productive time. My mentor and other team members were very helpful and polite with code reviews, and I learned a lot from them. They were also very helpful in discussing technical difficulties with me to deepen my understanding. The company encouraged working remotely, but it was great that I could come to the office if I wanted. LeapMind is a great place to work!
References
[1] G. Nie et al., arXiv [cs.CV] (2022), (available at http://arxiv.org/abs/2202.03716). [2] M. Courbariaux et al., arXiv [cs.LG] (2016), (available at http://arxiv.org/abs/1602.02830). [3] Z. Liu et al., arXiv [cs.CV] (2018), (available at http://arxiv.org/abs/1808.00278). [4] I. Loshchilov and F. Hutter, arXiv [cs.LG] (2016), (available at http://arxiv.org/abs/1608.03983).