September 24, 2021
Summer Internship 2021 – Mario – Finding Lottery Tickets via Gradient Descent!

Hello and welcome to my LeapMind Summer Intern summary post!
About Myself
I'm a German-born, Spanish-raised computer scientist with a passion for Neural Networks and Natural Language Processing. I'm a master student at the University of Tokyo and got the opportunity to join LeapMind for a summer itern program. Feel free to follow me on GitHub or Twitter! I also have my own blog where I (very) occasionally write some stuff.
Let's start by giving some background about the topic at hand before I show you the results I obtained!
The Lottery Ticket Hypothesis

Model pruning is a method to reduce the number of active weights in a neural network, for the purpose of decreasing model size and induce stronger regularization. A recent research direction called The Lottery Ticket Hypothesis talks about how it is possible to find subnetworks that perform equally well (or even better!) than their full-sized counterparts, while also converging faster. This idea has prompted a number of follow-up works on pruning and lottery tickets and their relationship with the nature of how neural networks learn.
Finding Supermasks
One of the most notorious findings that spawned from the concept of Lottery Tickets is the supermask. This mightly creature is capable of pruning a randomly initialized model in such a way that it achieves full-sized model performance, but without ever changing the weights. Let that sink in for a moment! You randomly initialize the weights of a model, and then apply a certain mask, which zeroes-out a large amount of the weights. Without any weight training, this model performs extremely well on the test set of a certain task.
So what is this black magic? How do we obtain these supermasks? The answer is: gradient descent! Instead of calculating the gradients with respect to the weights, we compute the gradient on the mask and take a step towards a mask that reduces the target loss. Although applying a mask sounds like a non-differentiable task, via some tricks this is a totally possible. The algorithm that trains these masks is called edge-popup. Refer to the paper and its code for details!
Supermasks for Binarized Models
The Multi-Prize Lottery Ticket Hypothesis paper talks about how we can find very robust binarized models via the supermask method. Models with binarized weights and activations are notoriously difficult to train, and here at LeapMind we wished to investigate the potential of this method to help us improve our own models.
What I Discovered
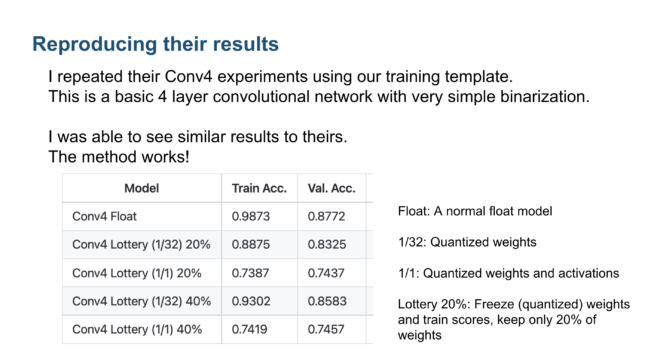
Just like in the Multi-Prize Lottery paper, a fully binarized lottery model remains 10%~20% below in accuracy against a standard weight-trained float model, especially for larger datasets such as ImageNet. However, comparing a binarized lottery model against a weight-trained binarized model is a different story! Here we can see extremely competitive results depending on the model configuration and dataset.
However, an important realization can be made to further improve results. The idea of freezing the weights and performing only mask-optimization is interesting from a theoretical point of view and helps these research papers get published, but when it comes down to the practical benefit, there is no reason for us to restrain ourselves in such a way! Why not combining the power of supermasks with the old-fashioned but well-known weight-training?
It turns out that supermask training in combination with normal weight-training acts like a strong regularizer, helping to improve generalization and avoid learning spurious correlations. Overall, we obtain much better training curves when training an unfrozen model with supermask training.
Additionally, assuming the existence of a powerful sparse-multiplication library, we can speed-up inference time of these models due to the fact that the weights are masked and thus very sparse.
Conclusions
This summer internship was extremely exciting and I learned a ton of things. First and foremost, I got to dive deep into the theoretical guts of model pruning, lottery tickets and edge-popup supermask training. An additional, and in my opinion even more valuable experience was to see firsthand how a large, cutting-edge deep learning repository is organized and maintained. I learned how to structure complex research experiments aiming for clarity and reproducibility. This will be my biggest takeaway for sure!