2023年9月25日
量子化ニューラルネットワークの枝刈りによる超高速推論の検討 / Investigating Super-fast Inference by Pruning Quantized Neural Networks
はじめまして。LeapMindでインターンをしていた大神です。 夏休みの2ヶ月間、Network Development Kit (NDK)チームに参加させていただきました。この記事ではインターン期間中の取り組みや、インターンを通して感じたことを書きたいと思います。
Greetings, my name is Ogami and I was an intern at LeapMind. I joined the Network Development Kit (NDK) team for two months during the summer vacation. In this article, I would like to write about my efforts during my internship and what I felt through the internship.
今回のインターンでは、Binary domain generalization for sparsifying binary neural networks(*1) という論文で提唱された量子化ニューラルネットワークの枝刈りの手法をEfficiera NDK(LeapMindが開発している量子化ディープラーニングモデルを開発するためのAPI)上で再現することを目標にしました。
The goal of the project was to reproduce a method of pruning quantized neural networks proposed in the paper Binary domain generalization for sparsifying binary neural networks on Efficiera NDK (API to build quantized neural networks that are supported by Efficiera IP).
概要 / Overview
ニューラルネットワークの推論コストを削減するための有力な手法として、(1)重みや活性化関数の出力を少ないビット幅で表現する量子化 と(2)重みの一部を0にする枝刈り があります。
この論文では、重みの量子化手法と誤差関数を工夫することで、モデルのパフォーマンスを著しく落とすことなく量子化と枝刈りを同時に行うことができると主張しています。画像分類CIFAR10、 CIFAR100、ImageNetで実験を行い、CIFAR10、 CIFAR100では95%の重みを枝刈りしても枝刈りをしない場合と同等の性能を示せること、ImageNetではAccuracyが3.4%下がるのと引き換えに、90%の重みを枝刈りすることができるという結果を示しています。
Two promising methods for reducing the inference cost of neural networks are (1) quantization, which represents the output of the activation function, the weights, with a small bit width, and (2) pruning, which sets some of the weights to zero.
This paper argues that by devising the error function and quantization method used to quantize neural networks, it is possible to obtain quantized and pruned networks without significantly degrading the performance of the model.Experiments were conducted with CIFAR10, CIFAR100, and ImageNet, and the results show that with CIFAR10 and CIFAR100, pruning 95% of the weights can produce the same Accuracy as without pruning, and on ImageNet, 90% of the weights can be pruned in exchange for a 3.4% reduction in Accuracy.
General Domain Quantizer
多くの量子化手法では重みを2値化する際に、0より小さい値は-0.5に、0より大きい値は0.5に変換するというように0に関して対称な値に2値化します。しかし、この論文で提案されたGeneral Domain Quantizerでは、0より小さい値はɑに、0より大きい値はβに変換し、ɑとβの値もbackpropagationで最適化することにより、モデルの表現力をなるべく保持しようとしています。
In most quantization methods, the weights are binarized to symmetric values with respect to 0, such that values less than 0 are converted to -0.5 and values greater than or equal to 0 are converted to 0.5. The General Domain Quantizer proposed in this paper, however, converts values less than 0 to ɑ and values greater than 0 to β. The values of ɑ and β are also optimized by backpropagation to preserve the expressiveness of the model as much as possible.
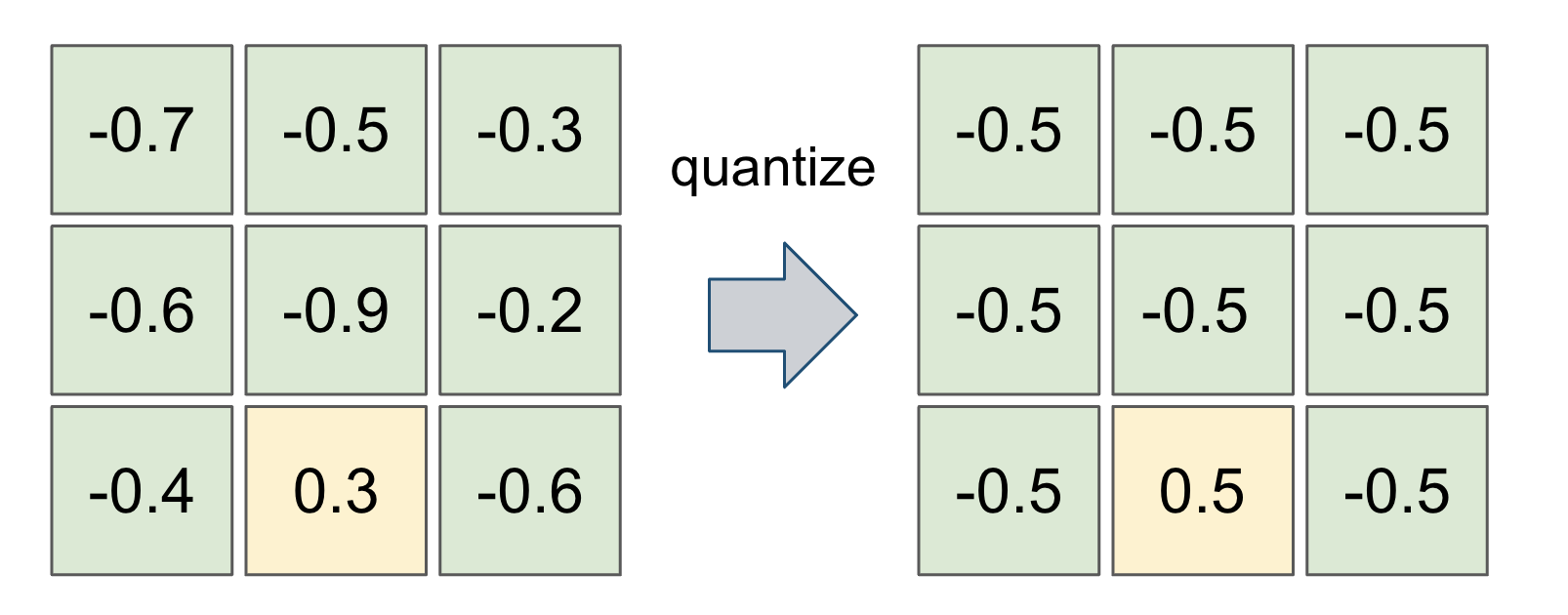
図1: 対称な重みへの量子化 / Quantization into symmetric weight (XNOR-Net(*2))
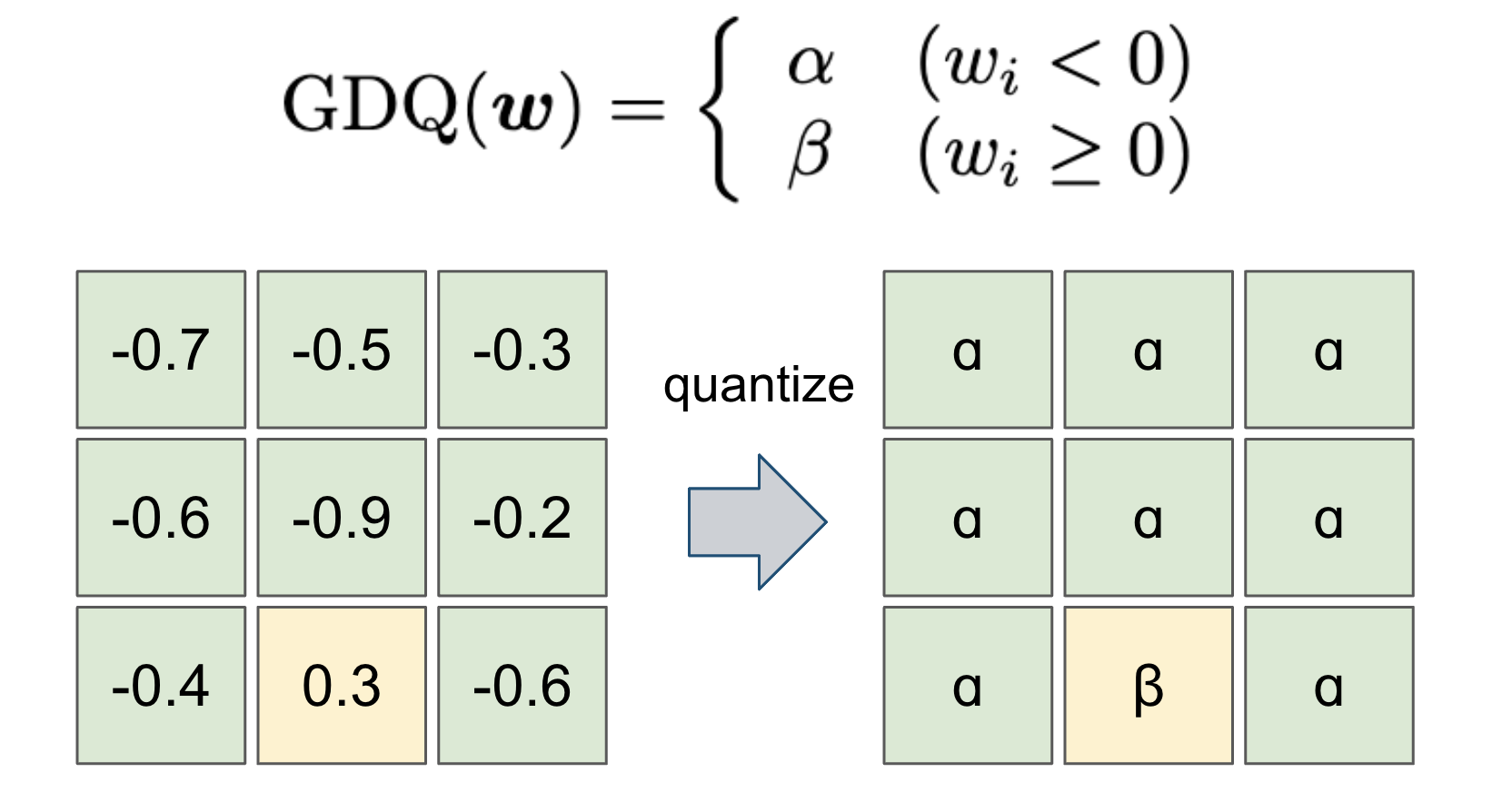
図2 General Domain Quantizerによる重みの量子化
General Domain Quantizerによって2値化された重みと入力との畳み込みの計算は図3のように分割して行われます。上側の計算については、重みがスパースである時(特に1の重みが0個または1個の時)、畳み込みの計算は高速に行うことができます。また、下側の全て1のカーネルの計算は入力のチャネルが同じであれば全ての出力チャネルについて結果が等しいため、一度だけ計算を行えば十分です。そのため、量子化後にβの値をとるような重みを減らすような枝刈りを行うことによって、モデルの推論を高速化することができます。
The computation of the convolution between the weights binarized by the General Domain Quantizer and the input is performed as shown in Figure 3. For the upper side of the computation, when the weights are sparse (especially when there is zero weight kernel or one hot kernel like in the figure., the convolution computation is fast. Also, for the lower side, computation of the all 1's kernel only needs to be done once, since the result is equal for all output channels if the input channels are the same. Therefore, the inference of the model can be speeded up by pruning to reduce the weights such that they take on a value of β after quantization.
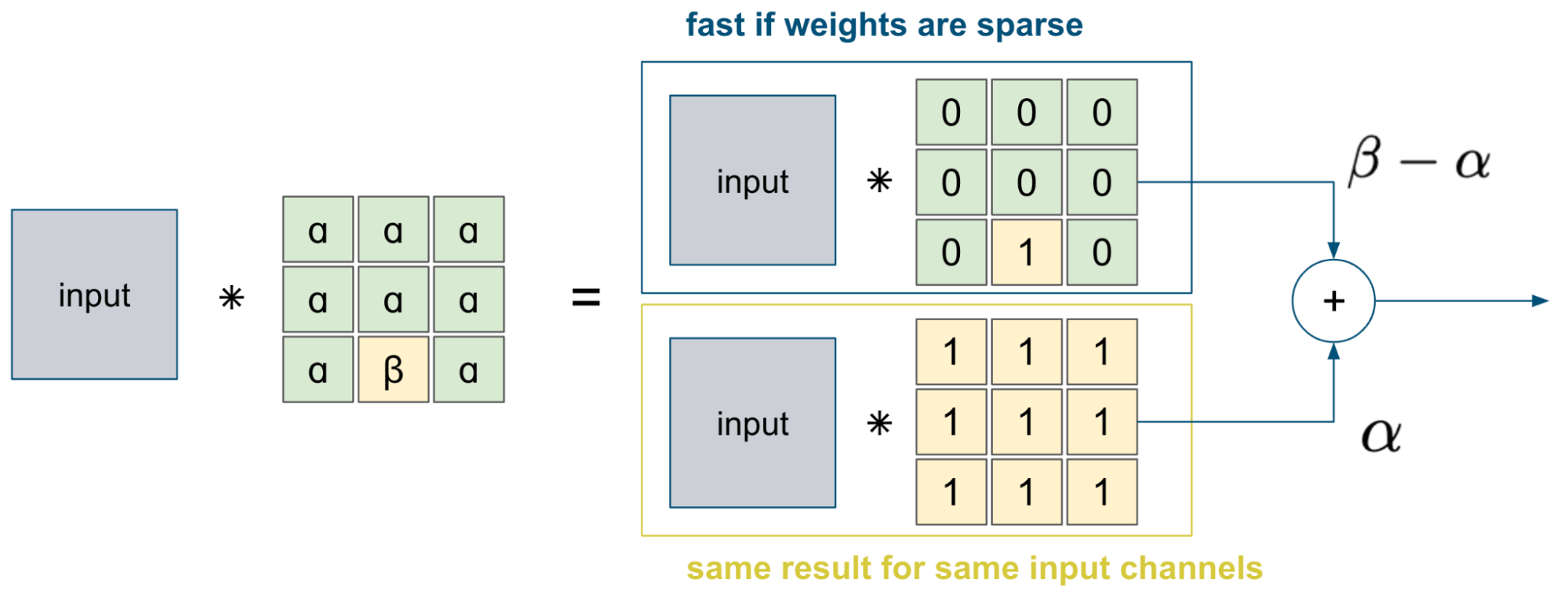
図3 General Domain Quantizerで量子化された重みの畳み込み計算
Sparsification Regularizer
2値化によってβへと変換される重みの割合(pos_weight_ratio)が所望の割合(EC)を超えている場合にはペナルティをかけるような誤差関数を分類誤差に加えます。例えば、EC=5%と設定すると、95%の重みが枝刈りされるように学習が進みます。
A loss function is added to the classification error that penalizes if the percentage of weights converted to β by quantization (pos_weight_ratio) exceeds the desired percentage (EC). For example, setting EC=5% will cause learning to proceed so that 95% of the weights are pruned.
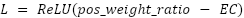
プロジェクトの目標 / The Goal of the project
Efficiera NDKに実装されている量子化ニューラルネットワークに対して、論文中で提案された手法を適用し学習を行うことで、多くのデータセットでモデルの精度を落とすことなく畳み込み層の重みの枝刈りを行うことを目指しました。現在のEfficiera NDKでは枝刈りが行われていないため、性能を落とすことなく枝刈りを行うことができれば推論の高速化が見込めます。
We applied the method proposed in the paper to a quantized neural network already implemented in Efficiera NDK to prune the convolutional layer weights without degrading the accuracy of the model on various datasets. Since the current Efficiera NDK does not perform pruning, it is expected to speed up inference if pruning can be performed without compromising performance.
取り組んだこと / What I did
まずはニューラルネットワークの量子化に関する論文やNDK上での実装を読み、量子化に関する基礎知識を身につけるところから始めました。普段はあまり意識していないようなニューラルネットワークの低いレイヤーの部分について考える機会になり、深層学習に関する理解度が上がったように思います。
I started by reading papers on quantization of neural networks and their implementation on NDK to acquire basic knowledge about quantization. I think this gave me an opportunity to think about the lower layers of neural networks, which I am not usually aware of, and improved my understanding of deep learning.
その後、再現実装のターゲットとなる論文を読み、NDK上で実装するメリットや、新たに実装するべき機能、どのような実験を行う必要があるかについて確認しました。そして実際に、論文中で提案された量子化手法、誤差関数、モデルのスパースさを測定する機能を実装しました。この段階を通して、新しい技術を取り入れていく際に必要なプロセスが理解できました。さらに、社員の方が実装した既存のコードを読んだりレビューを受けたりすることで、自分のコードの質を上げることができました。
After that, we read the papers targeted for reproduction and implementation, and confirmed the advantages of implementing on NDK, what new functions should be implemented, and what kind of experiments need to be conducted. We then actually implemented the quantization method, the loss function proposed in the paper, and the function to measure the sparsity of the model. Through this phase, I gained an understanding of the process required to incorporate new technologies. Furthermore, I was able to improve the quality of my code by reading existing code implemented by employees and receiving reviews.
必要な機能を実装した後に、NDK上での性能を確認するための実験を行いました。論文と同様にCIFAR10、CIFAR100、ImageNetで実験を行いました。CIFAR10、CIFAR100では95%の重みを枝刈りし、枝刈りをしない場合と同等の性能を示すことを目指しました。ImageNetでは90%の重みを枝刈りし、5%以内の性能低下に抑えることを目指しました。
実験をしてみると、訓練の途中で誤差が発散する、枝刈りが進まないなどの問題が起こり、思うように再現実験が進みませんでした。初めは著者実装に近いハイパーパラメータを使用していたのですが、実際にはかなり異なる値を使うことや、論文中では特に言及されていなかったGeneral Domain Quantizerのɑとβの初期値の調整など工夫が必要でした。
After implementing the required functionality, we conducted experiments to verify its performance on the NDK. As in the paper, experiments were conducted on CIFAR10, CIFAR100, and ImageNet. Our goal with CIFAR10 and CIFAR100 was to prune 95% of the weights and show performance comparable to that without pruning. Our goal with ImageNet was to prune 90% of the weights and save accuracy reduction to within 5%.
In our experiments, we encountered problems such as diverging errors in the middle of the training, and the pruning did not proceed as expected, so we were unable to replicate the experiment. Initially, we used hyperparameters that were close to the authors' implementation, but in practice it was necessary to use very different values. In addition, we had to devise adjustments to the initial values of ɑ and β for the General Domain Quantizer, which were not specifically mentioned in the paper.
試行錯誤を重ねた結果、最終的にはCIFAR10、CIFAR100では目標を達成することができました。ImageNetではおよそ6%の精度低下が起こり、惜しくも目標を達成することができませんでしたが、NDK上でも論文に近い結果を示すことができ、今回実装した枝刈りの手法が有望であることが確認できました。
機械学習の実験結果は数多くのパラメータに依存しているため、良い結果や知見を得るために必要な実験の数は自分が思っている以上に多いということがわかりました。Leapmindでは多くの試行錯誤を行いその結果を整理できるような実験環境があったためスムーズに実験を進めることができました。
After much trial and error, we finally achieved our goal with CIFAR10 and CIFAR100, and although we could not achieve our goal with ImageNet due to an accuracy loss of approximately 6%, we were able to show results similar to those in the paper on NDK, which confirmed the promise of the branch pruning However, we were able to show results on NDK that were similar to those in the paper, confirming that the branch pruning method implemented here is promising.
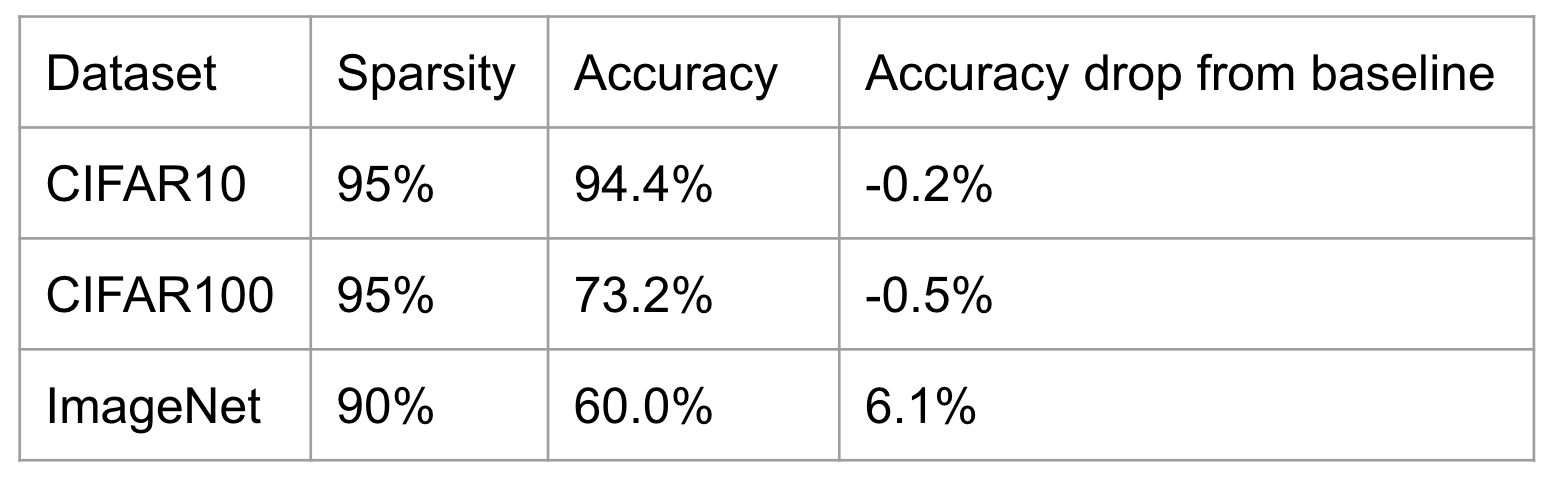
図4 実験結果

労働環境について / Working Environment
インターンシップ開始時点ではニューラルネットワークの量子化についてはほとんど何もわからない状態だったのでした。しかし、メンターの方がキャッチアップのためのマテリアルを準備してくださっていたおかげで、量子化についての知識やLeapmindでの開発のプラクティスを理解し比較的早くプロジェクトに着手することができました。新しく入ったメンバーがストレス少なくプロジェクトに合流できる環境が整えられている点がとてもありがたく感じました。
また、コードレビューを通して質の高いコードを書くことへの意識が身についた点、機械学習の実験管理やプロジェクトのコード管理の方法を学べた点がとても良かったです。さらに、英語でコミュニケーションを取りながらプロジェクトを進めることや、リモートメインで働くことは初めての経験で、とても新鮮でした。
At the start of my internship, I knew almost nothing about neural network quantization. However, thanks to the mentor who prepared materials for me to catch up, I was able to understand the knowledge of quantization and the practices of development at Leapmind and start working on the project relatively quickly. I really appreciated the fact that the environment was set up so that new members could join the project with less stress.
I also appreciated the fact that I gained an awareness of writing high-quality code through code reviews, and that I learned how to manage machine learning experiments and project code. Furthermore, it was my first experience to work on a project while communicating in English and working mainly remotely, which was very fresh.
参考 / Reference
- Riccardo Schiavone, Francesco Galati, and Maria A Zuluaga. Binary domain generalization for sparsifying binary neural networks. arXiv preprint arXiv:2306.13515, 2023.
- Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary convolutional neural net-works. In ECCV 2016.