
Efficiera Models
AIモデルの軽量化手法の一つ量子化を、極限の1bitまで突き詰めた、「極小量子化技術」を用いて、エッジAIの抱える問題を解決することができます。
エッジデバイス向け高性能AIモデル
AIをエッジデバイス上で動かす上で、コンピュータリソースや消費電力の制限、メモリの制限など、いくつかの問題が存在しており、大きな課題になっています。
LeapMindは、ハードウェアの問題と同じくらい、ソフトウェアの問題解決が重要と考えており、AIの計算方式自体を書き換えることで、これらの大きな課題を解決しようと試みています。
実用的なAIモデルはより多くの(深い)畳み込み層から構成されるため、全体の演算量が大規模になります。この演算量を量子化せずに浮動小数点数を用いて行うと、大量の浮動小数点演算器(FPU)を用いて、高い動作周波数で動作させる必要があり、このことがエッジデバイスでAIモデルを実用的に動作させることを難しくしています。
極小量子化を用いれば、回路面積の大きいFPUを使う代わりにビット演算を用いることができ、回路規模を劇的に削減、さらにweightやactivationを保持するためのRAMも削減し、メインメモリに対するアクセスの帯域を減らすことができます。
LeapMindは、これらの技術を用いて、エッジデバイスにおける様々なタスクを強力にサポートする極小量子化AIモデル郡を提供いたします。
FEATURES
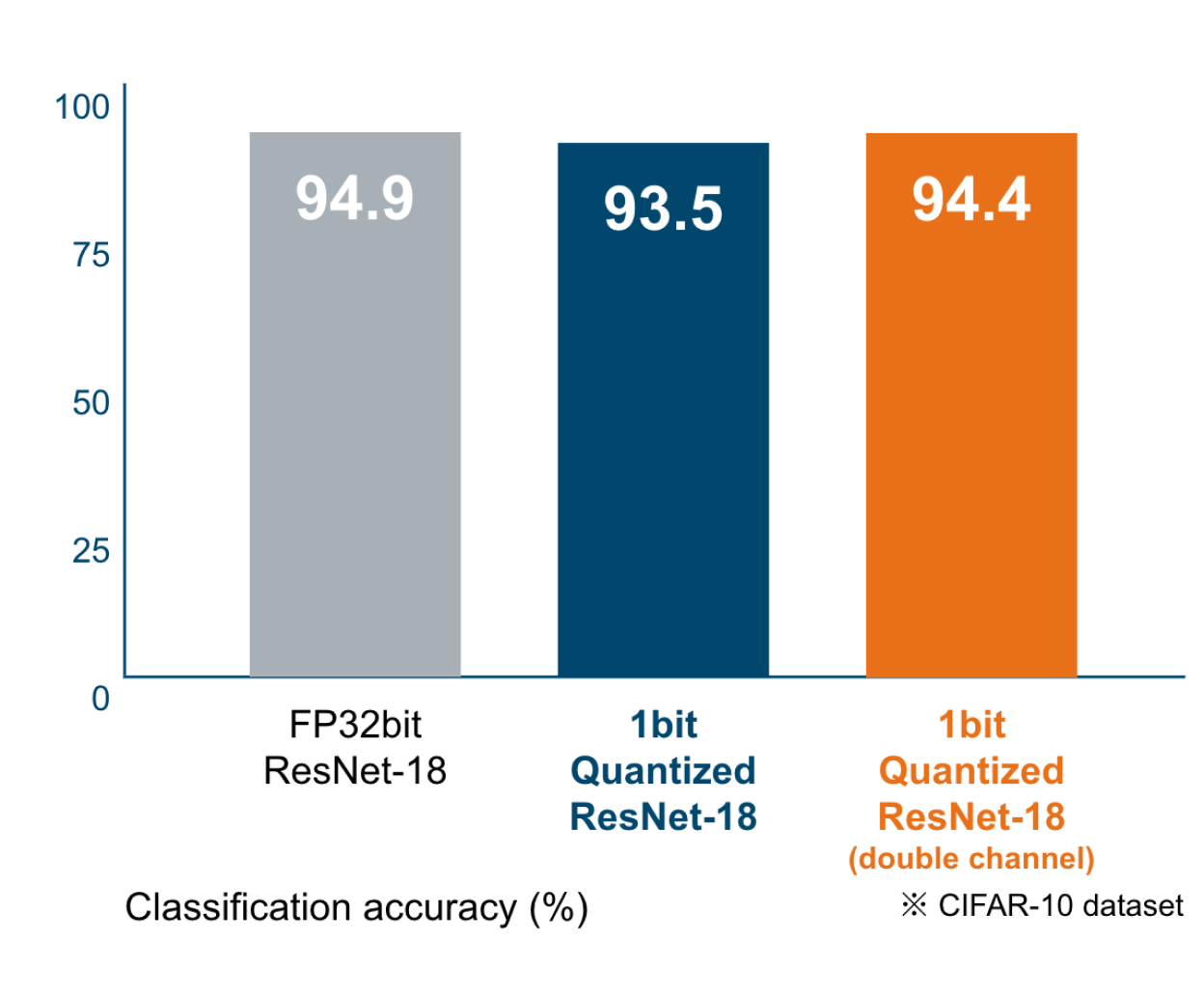
精度劣化を極限まで抑える
LeapMindでは、精度劣化を防ぐために、いくつかの工夫をしています。代表的なものとして、量子化認識トレーニング、ダブリングチャネル、ピクセルエンべディングになります。
量子化認識トレーニングは、極端に低いビット数の量子化には非常に重要な技術です。量子化ビット数が極端に少ないネットワークは、チャンネル数を2倍(ダブリングチャネル)にしても同等の精度を達成できます。
また、第1畳み込み層への入力データは量子化が難しいとされていますが、ピクセルエンべディングという、当社独自の技術を用いて、この第1畳み込み層の量子化に成功しています。
高解像度入力でリアルタイム画像処理
高解像度入力での計算は、必要な計算量が増大し、リアルタイム処理をFull Precisionでエッジデバイスに実装することは、計算量、メモリ、帯域の関係から不可能とされていました。
しかし、モデルサイズの圧縮とメモリ帯域に考慮した実装を行うことで、これが実現可能になります。
マルチチャネル/高解像度入力でリアルタイム画像認識
物体検出などの画像認識タスクにおいては、認識精度とモデルサイズがトレードオフになりますが、Efficiera Modelsは、例えば、PASCAL VOC 2007+2012のdatasetを用いたAIモデルの場合、以下のような性能を達成、性能要求が厳しい利用用途でも実現することが可能になります。(比較参考:MobileNetV2 SSD-Lite: mAP(0.5): 0.686)
• mAP(0.5): 69.8
• 30.6GOPS/frame
• FPS(動作周波数500MHz): 401


TECHNOLOGY

動画を再生すると音声が出ます(字幕あり)
極小量子化技術
ディープラーニングに極小量子化技術を適用することで、モデルが軽量化され、容量と計算量を大幅に削減できます。しかも、性能の劣化は最小限に抑えることができます。
具体的には、推論モデルを構成するパラメータを、通常用いられる単精度浮動小数点数(32ビット)から1ビットまたは2ビットに置き換えることで、軽量化を達成します。
一般的には、性能の劣化を起こさない限界は8ビットまでとされていますが、LeapMindでは、8ビットを大きく下回る1ビットのWeight(重み係数)、2ビットのActivation(入力)という組合せでも性能をほとんど劣化させないことに成功しています。
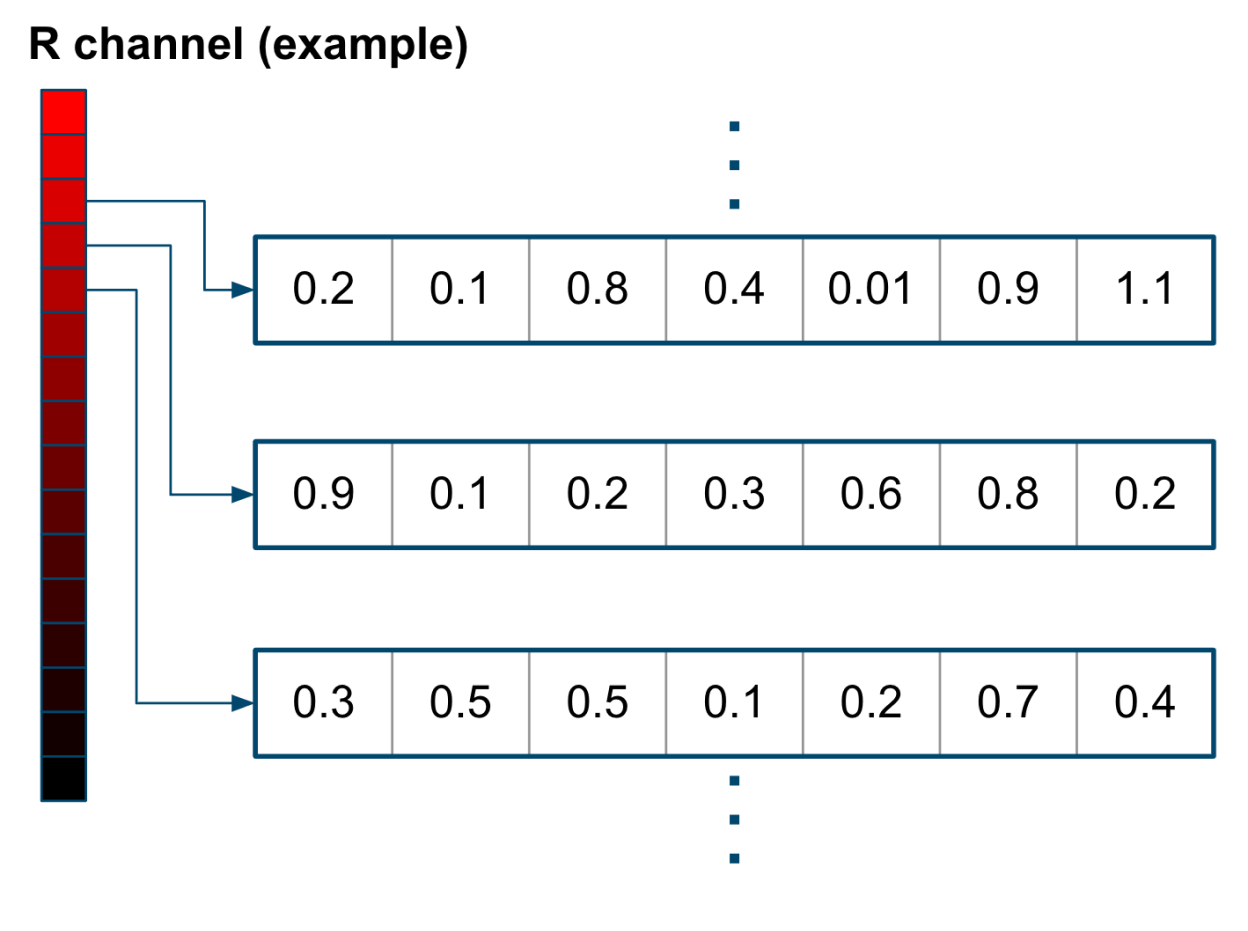
Pixel Embedding(畳み込み演算)
推論精度に与える影響が大きいニューラルネットワークの第1層の量子化に、独自技術である「Pixel Embedding(畳み込み演算)」を入力データの変換手法として用いて、最小限の精度劣化にとどめています。
入力データに対する最初の畳み込み演算は一般的に浮動小数点を使用したり、よりビット数の多い整数演算を用いるのに対してLeapMindでは、入力データを複数チャネルの2ビットデータにエンコードします。これによって最初の畳み込み層から極小量子化技術を使用することが可能です。