2019年11月26日
Blueoilチームでサマーインターンシップ

こんにちは! LeapMindでインターンしました井上と申します。
私は8月と9月の二ヶ月間、Blueoil Divisionと呼ばれる部署に所属し、同じ時期にインターンを行ったOscarさんとともに、Blueoilを用いた新しい深層学習タスクの開発に携わりました。
この記事ではそのプロジェクト及び成果・感想に関して、特にBlueoilを使用して実装を行った開発者としての視点から、説明しようと思います。
Ⅰ.インターンシッププロジェクトについて
Blueoilと量子化について
BlueoilはLeapMind社で開発されているオープンソース深層学習フレームワークでtensorflowを基に開発されています。このBlueoilは以下の二点の特色を持ちます。
(i) ニューラルネットワークの量子化ツールを提供 (Quantization) (ii) ARMやFPGA等の低消費電力アーキテクチャ上で効率的に動作するモデルを生成する点 (Edge Computing)
深層学習モデルは平たく言えば、行列演算・畳み込みと非線形変換の巨大な塊です。通常この演算は32 bitや64bitの浮動小数点を用いて実装されますが、ARMやFPGAといったアーキテクチャではこの浮動小数点の高速な計算が困難です。また高性能なCPUやGPUの導入は消費電力やコストの観点から、特にリソースが限られるEdge Computingでは現実的ではありません。
そこで登場するのは、量子化(Quantization)と呼ばれる技術です。量子化は行列の要素及び非線形変換を低bitの要素に近似する技術を指します。特にBlueoilでは深層学習モデルが2 bit以下 (高々2^2=4値しか取りえない) で量子化されます。この極端な量子化により、推論速度の向上が期待される他、乗算器を省略できるためFPGAで実装した際に劇的に回路面積を抑える事が可能になります。
Blueoilではまた量子化されたモデル専用の学習アルゴリズムが提供されます。さらにtensorflowをベースに開発されているため、tensorflowのAPIを使える他、量子化する演算を自在に選択・設計できます。そして設計者は、データセット及び推論モデルを定義しさえすれば、ARM・FPGA上で高速に動作する深層学習推論モデルを容易に構築することができます。
Optical Flow Estimationの深層学習モデル
さて今回のインターンシップのプロジェクトですが、ずばりOptical Flow Estimation (OFE)を行う深層学習モデルのBlueoil上での構築です。Optical Flowとは文字通り、視覚的な物体の動き(ベクトル)を指し、特にOFEはOptical Flowを二枚のデジタル画像から推定するタスクを指します。OFEは、物体の運動の解析やロボット等の運動制御の他、動画の圧縮や安定化に用いられる等幅広い応用が期待されます。
OFEには疎な推定と密な推定があるのですが (Fig. 1)、今回は特にFig 1.の下図のような、全ピクセルの動きを推定する密なOFEの実装を目標としました。

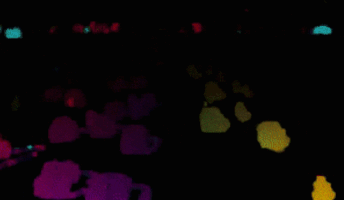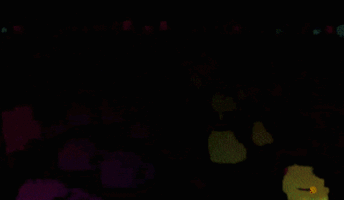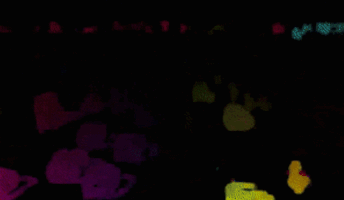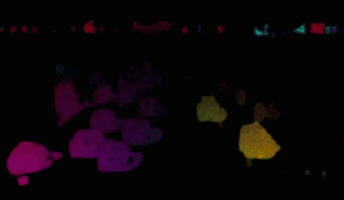
Figure 1 OFEの例。動画像から動画像内の物体の動きを推定する。
上動画は疎な推定、下動画は全ピクセルに対する密な推定。
https://nanonets.com/blog/optical-flow/ より引用。
さてこの密なOFEに関して、近年FlowNetS [P. Fischer et al., 2015] とよばれる深層学習を使用した手法が提案されました。DeepFlow [P. Weinzaepfel et al., 2013]やEpicFlow [J. Revaud et al., 2015]等、密なOFEを推定するアルゴリズムはこれまでいくつか提案されてきたのですが、計算量が大きくリアルタイムでの推定が困難でした。またOpenCVで実装されているGunnar Farneback法 [G. Farnerbäck 2003]はCPU上で高速に動作するものの、近傍pixelのみを参照するため大きな変位を推定することができません。FlowNetSでは、Convolutional Neural Networkが用いられend-to-endで学習・推論されます。そしてGPU上を用いたデモンストレーションで5~10FPSに達することが報告されています (Fig. 2)。
しかしながらFlowNetSでもモデルのパラメータ数が大きくGPUやARM・FPGA上では実用的な速度で動作しません。インターンシッププロジェクトの最終目標は、このFlowNetSをBlueoilを用いて量子化し学習を行い、低消費電力アーキテクチャ上で高速に動作させることです。OFEを低消費電力のデバイス上でもリアルタイムに動作できれば、様々なデバイスでOFEが実装可能になることを意味し、応用の幅が大きく広がります。

Figure 2 FlowNetSのデモンストレーション。 https://www.youtube.com/watch?v=k_wkDLJ8lJEより引用。 デモンストレーションはGPU上で行われ5~10FPSを達成。
LMFlowNetの開発
FlowNetSはFig 3.に示されるような構造を持ちます。FlowNetSはいわゆるEncoder / Decoder型の構造を持ち、大まかに特徴を抽出するEncoder (convolutionで構成される)と、実際のflow imageを出力するDecoder (deconvで構成される)が組み合わさっています。
このFlowNetSをそのまま量子化したいところですが、Blueoil上の諸々の制約によりそのままでは量子化する事ができません。そこでBlueoil上で動作するようにいくつか要素に変更を加えたLMFlowNet (Fig. 4)を本プロジェクトで開発しました。具体的には、例えばconvolution層のstrideがspace_to_depthを活用することで近似的に実装されています。
さらに計算時間及び開発キット(DE10-Nano)のメモリの問題から、最終的にFig. 5に示されるようなかなり単純化されたモデルを今回採用しました。なお、今回は連続値を出力する回帰タスクのため、この第一層と最終層の2つの層は量子化せずにそのまま32 bitの浮動小数点のまま計算します。
学習は、FlowNetSにおいて用いられたFlying Chiarsを用いて行いました。更に過学習を防ぐためData augmentationを逐次行いデータセットを変換します。
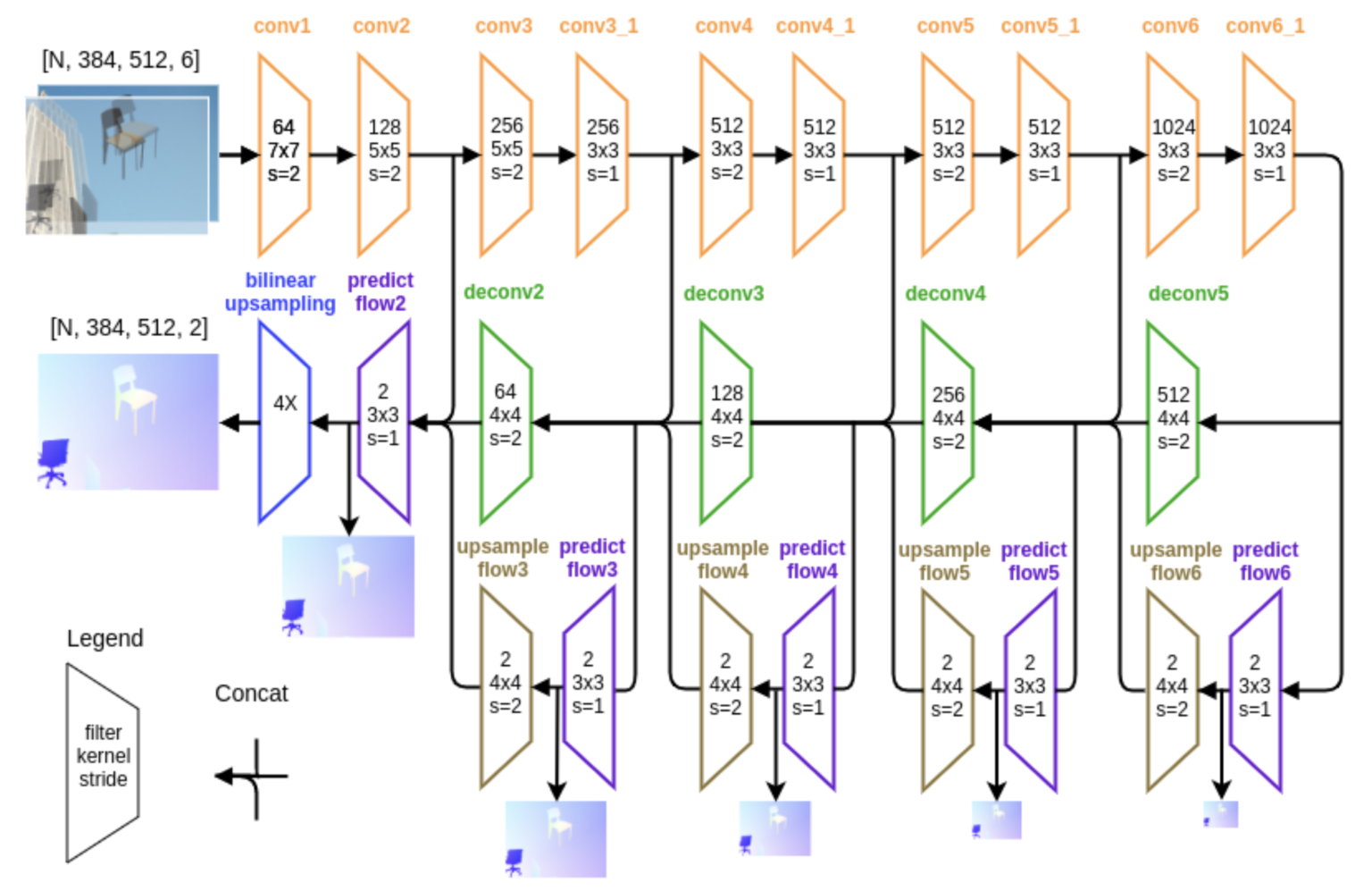
Figure 3 FlowNetSの構造。基本的にconvolution layerとdeconv layerから構成される。
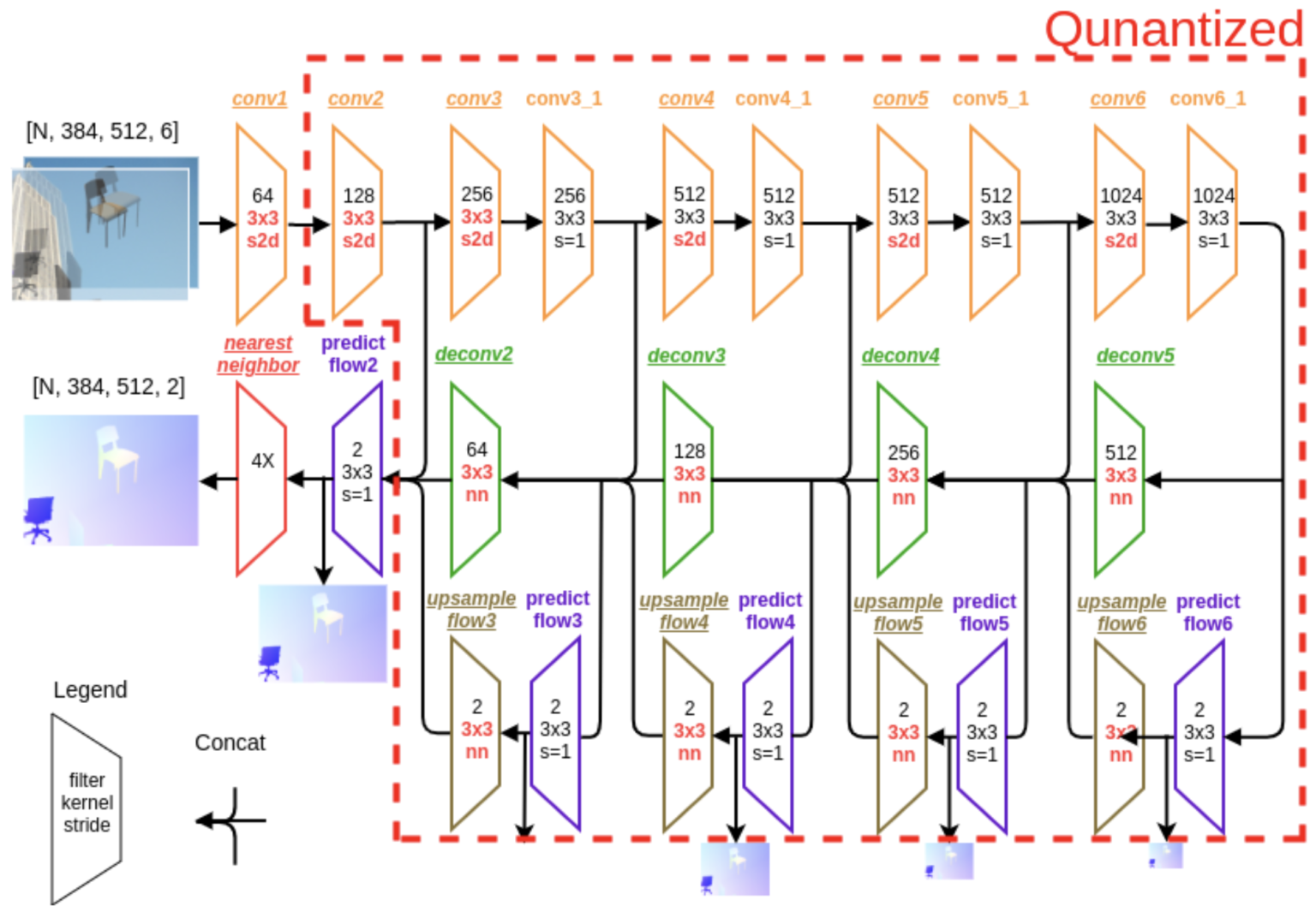
Figure 4 LMFlowNetの構造。Blueoilでサポートされている演算のみを採用し構成。
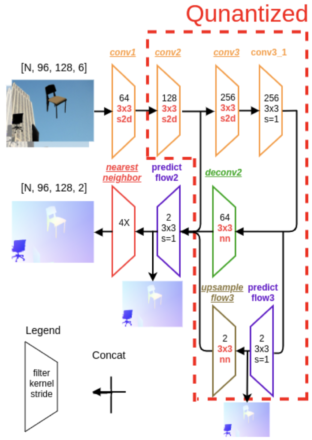
Figure 5 最終的に採用したLMFlowNetの構造。ARM / FPGA上で動作させるため、画像サイズを1/16にした上で更に層の数を大幅に減らした。
Ⅱ.成果
推論速度の比較
まず推論速度を比較し、量子化による速度向上の効果を確認します (Table 1)。表からわかるように量子化された場合、x86 CPU (ノートPCのCPU; Core(TM) i7-5500U)上でおよそ2.5倍, ARM上でおよそ4倍, FPGA上でおよそ6倍推論速度が向上することがわかりました。さらに量子化されない1層目のパラメータ数を減らした場合、その速度向上の効果がより顕著に現れます。このようにLMFlowNetを構築しモデルを量子化させると、期待された通り推論速度が大幅に上昇しました。
| 推論速度 [ms] (5回平均) | 量子化なし (連続モデル) | 量子化あり +64 channels | 量子化あり+ 32 channels | 量子化あり+ 16 channels | 量子化あり+ 8 channels |
|---|---|---|---|---|---|
| x86_64 (AVX使用) | 35.2 | 14.3 | 10.9 | 8.56 | 7.3 |
| ARM | 875.6 | 204.2 | 140.8 | 116.0 | 101.7 |
| FPGA | 836.6 | 130.9 | 94.7 | 78.1 | 67.8 |
Table 1 推論速度の比較。実験では通常の連続モデル / 量子化モデルに加え、量子化モデルにおいて量子化されない1層目のチャネル数を減らしたモデルに関しても検証した。
推論精度の比較
次に推論の精度を比較し、量子化が与える推論精度への影響を調べます (Table 2)。推論精度の評価はFlying Chairsのバリデーションデータ(学習に用いていないデータ)を用いて行いました。OFEではEnd Point Errorと呼ばれるground truthデータと出力データ間の距離(誤差)を測る指標が一般的に用いられ、それを用いて採用します。まず量子化を加えることにより、連続モデルと比較しておよそ1.5倍誤差が大きくなりました。またチャネル数を変える実験より、1層目のチャネル数がそこまで最終的な精度に影響を与えないことが読み取れます。
| 推論速度 [ms] (5回平均) | 量子化なし (連続モデル) | 量子化あり +64 channels | 量子化あり+ 32 channels | 量子化あり+ 16 channels | 量子化あり+ 8 channels |
|---|---|---|---|---|---|
| End Point Error | 6.403 | 9.448 | 9.263 | 10.625 | 9.311 |
Table 2 推論精度の比較。End Point Errorは正解データと出力との誤差を測る指標。
デモンストレーション
さて実際にデモンストレーションを行ってモデルの妥当性を検証します。まずは通常のx86 CPUが搭載されているノートPCでのデモンストレーションです (Fig. 6)。連続モデルと比較したとき、量子化モデルは若干ぼやけた画像が出力されているものの、どちらのモデルも手の動きの向きに合わせて対応する位置に出力される様子が観察されます。


Figure 6 ノートPC (x86_64)上でのデモンストレーション。上図は連続モデル、下図は量子化したモデルのデモンストレーション。FPSの値はそれぞれ(左) 実効的なFPS (右) 推論FPSを表す。右上の2画像を重ねてモデルに入力される。出力のflowは右下のcolor coding mapに対応されて出力される。
次はDE10 Nano (ARM + FPGA搭載)上でのデモンストレーションです。
連続モデルのFPSが1程度で、リアルタイムの描画から程遠いの対して、量子化モデルでは、DE10 Nano上でもFPSが10程度で実質リアルタイムに描画させることができました。このように量子化すれば5~10倍の速度で描画できることが確認されました。


Figure 7 DE10-Nano (FPGA + ARM)上でのデモンストレーション。上図は連続モデル、下図は量子化したモデルのデモンストレーション。
Ⅲ.まとめ・今後の課題・感想
まとめ
今回のインターンプロジェクトで、OFEの深層学習モデルを作成し(LMFlowNet)、Blueoilを用いて量子化を行いました。そして実際に推論精度をある程度維持しながら、ARMやFPGAといった低消費電力アーキテクチャ上で高速に動作させることに成功しました。
今後の課題
今後の課題は以下の三点が挙げられます。
(i) 1層目・最終層を含めた完全量子化
(ii) 前処理・後処理の最適化
(iii) アプリケーションの実装
まず、今回のLMFlowNetでは実装の制約の問題から1層目および最終層が量子化されていません。しかしながらこの浮動小数点での演算が特にFPGA上で律速となっており、量子化による高速化の効果が半減しているのが現状です。将来的に完全に量子化されることで、そのポテンシャルが完全に引き出されるでしょう。
次に前処理・後処理の最適化の必要性です。全体のプロセスにおいて推論はその一部にしか過ぎません。事実、今回のデモでも通信や前後の処理に無視できないほどの時間がかかっており、インターンのプロジェクトでもかなりの時間を前後処理の実装・調整に費やしました。量子化による恩恵を最大化するためにも、推論プログラム周辺のインターフェースの最適化がますます重要になります。
最後にアプリケーションの実装です。今回はOFEのみを実装しましたがそれ単体ではその価値が薄いです。OFEを用いた製品やサービスを構築することが、世の中で使われるためにも今後必要になるでしょう。
感想
短い期間でしたが、とても刺激的で楽しい体験をさせていただきました。また完全ではないものの新しいタスクを0から実装し、デモンストレーションを作成することができました。この様に成果を出すことができたのは、インターン生で同じプロジェクトに携わったOscarさん、メンターの飯塚さん、Yangさん、金井さんをはじめとするBlueoil Divisionのメンバー、その他LeapMindの皆様の助力のおかげです。この場で感謝申し上げます。
今回のインターンで特に学んだのはチームでプロジェクトを実装・遂行することの楽しさおよび大変さです。今回はメンターの飯塚さんの指導の下、Oscarさんと協力することで遂行しましたが、その分担や計画立案、仕事の割り振り・調整に関して多くの議論を交わしました。このようなチームとしてコーディングは、普段はなかなか機会がないだけに、大変貴重な体験だったと思います。
最後に
インターン生ながら、プロジェクトの細部まで深く携わることができます。
Edge computingに興味のある方、実際に深層学習を活用したモノを作って見たい方はぜひインターンに応募してみてください!
Ⅳ.参考文献
Two-Frame Motion Estimation Based on Polynomial Expansion
FlowNet: Learning Optical Flow with Convolutional Networks
DeepFlow: Large displacement optical flow with deep matching
EpicFlow: Edge-Preserving Interpolation of Correspondences for Optical Flow
オプティカルフロー(Optical Flow) — OpenCV-Python Tutorials 1 documentation