2021年8月26日
Boost your AI research with hydra+Lightning templates
Have you ever named your experiment rnet50_sgd-cos-lr1e-2_imnet200_augs-ver8?
Have you ever experienced that awkward silence when your manager asks you to reproduce an experiment,
which you cannot do, because you have overwritten original code and lost the initial value of a learning rate?
If your answer is yes, we have something for you.
Best practices
In AI research, your efficiency depends on how quickly you implement and deploy ideas. The efficiency of your team depends on how quickly they can reuse or reproduce things you crafted. For that reason, your team should implement a standardized protocol of communication and exchange of experimental setups.
At LeapMind, we use hydra along with PyTorch Lightning templates which we believe is the best practice for organizing AI research.
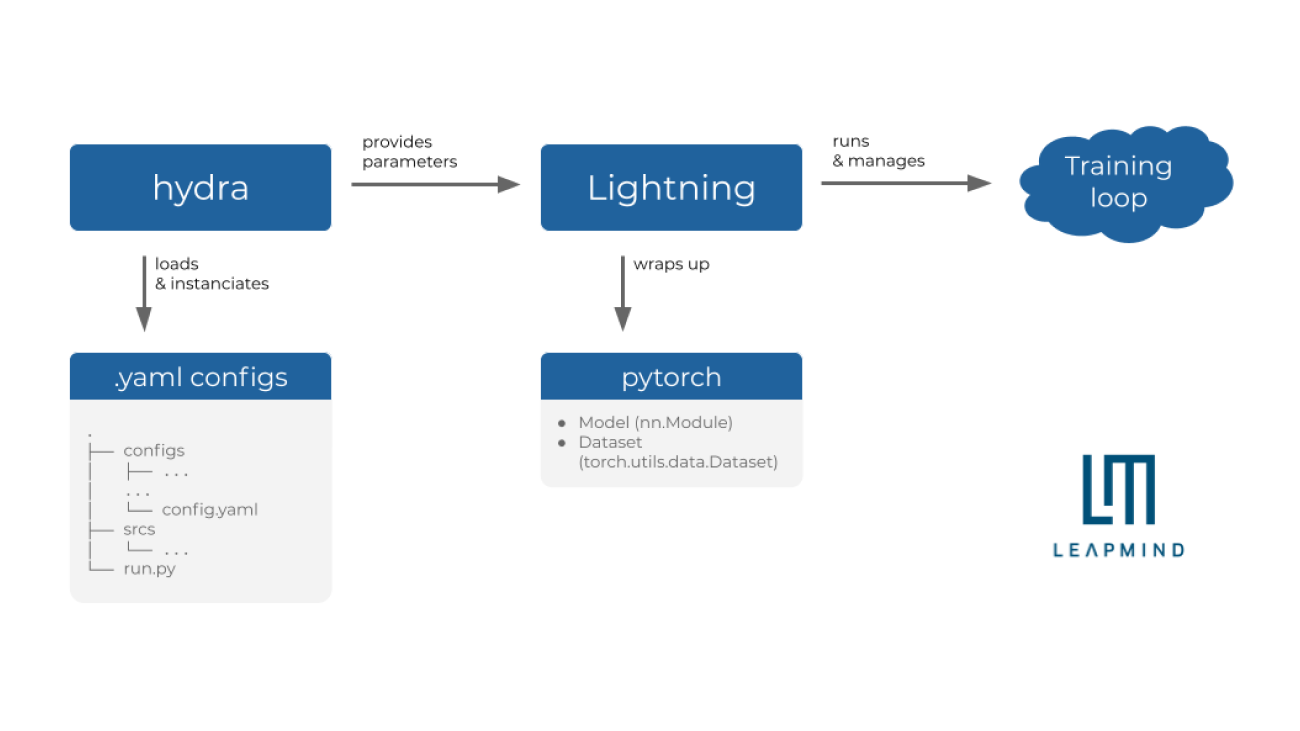
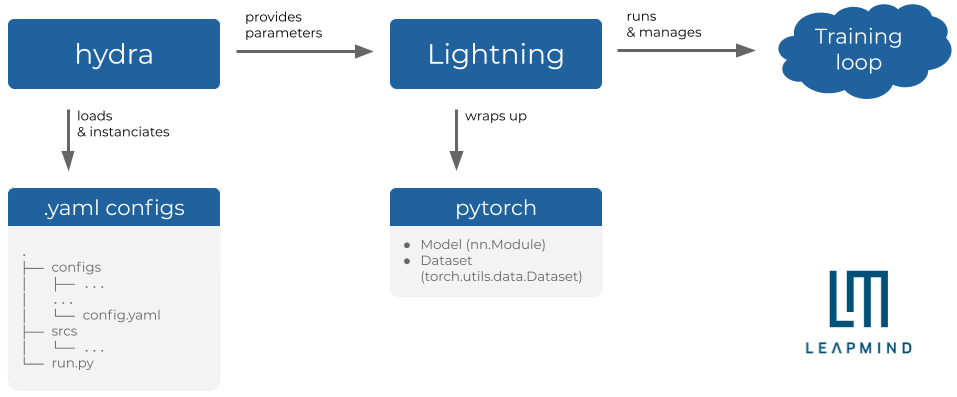 An overview of the environment we use at LeapMind.
An overview of the environment we use at LeapMind.
Organize your code: Lightning
Do you know this mantra? Data, gpu, feed forward, loss, zero grad, backward and logging? A lot of logging. Well, that’s the training loop which you saw a million times and which looks the same for every project. With an exception that sometimes it might get enormously long and nasty when adding more and more functionalities.
Here is where Pytorch Lightning comes in. Simply saying, it’s an organized way to write a training loop. Saying precisely: it’s a way to separate research and engineering by decoupling data from model and model from the training mechanism. Let’s look at an example.
LightningModule, the core of the Lightning, defines functions as: configure_optimizers(), forward(), training_step(), training_epoch_end().
Does it sound familiar?
Yes, this is where you write logic you would normally put in the loop.
This time, however, everything is neatly organized and – hold on to your code – Lightning will launch and manage the training loop for you.
The LightningModule defines forward() – does it mean the definition of your SuperResNet50 also goes there?
No! It stays where it’s always been, in superesrnet50.py, you only inject its dependency into the module and call it in the forward.
Similar happens to a dataset: it gets injected to a so called DataModule,
where only five methods are to be implemented: setup(), prepare_data(), {train, val, test}_dataloader().
As one might guess, the Lightning engine will call these methods whenever needed – so you don’t need to worry about the training flow.
Do you see an advantage of the Lightning now? Thanks to it, a model, data and training do not depend on each other, meaning you can easily replace any of them. Just imagine how much flexibility it gives when trying out new network architectures!
We won’t dive into technical details on the Lighting as its official documentation is a great resource.
Organize your experimental setups: hydra
The most common way to pass parameters to your system is, unfortunately, the argparse.
Let’s face the truth: these projects are just nasty – argparse-ing takes a lot of code which is often totally unreadable.
On the top, how does one know what arguments to pass to reproduce your experiments? Wrap them up in a .sh file?
Do we add more argparses as the project grows?
Certainly not.
Fortunately we have hydra. Thanks to hydra we can elegantly separate experiment configuration from code – in the same way we decoupled model and data using lightning. An example would tell it all.
Suppose we have a custom lightning module with following signature:
class SueperResNet50Module(pl.LightningModule):
def __init__(self, network: nn.Module, loss_fn: nn.Module, lr: float, epochs: int):
...
Note it’s already the Lightning module, meaning we would define training logic in there.
To instantiate the module, we could write the following .yaml file:
_target_: src.pl_datamodules.imagenet.CustomImageNetDM
network:
_target_: src.architecture.SuperResNet50
loss_fn:
_target_: torch.nn.CrossEntropyLoss
lr: 1e-2
epoch: 100
First, notice the special keyword, _target_ which specifies instantiatable objects.
As a value, it takes a package name followed by a class name.
It can be either a library (eg. torch.nn.CrossEntropyLoss), or our own package (src.pl_datamodules.imagenet.CustomImageNetDM).
Second, hydra will automatically attempt to match targets with object argument names, i.e. config value lr will be passed to the lr argument, and so on.
Do you need to run an experiment with a different learning rate now? It’s as easy as writing a new config file – clean and easy to reproduce.
But hold on, isn't it burdensome to create a new file which differs on only one value?
Absolutely not! Keep in mind that the goal is to create an environment where everything is easily reproducible
(one could suggest overriding hydra config at terminal level just for that one value – we strongly disrecommend it for the same reasons as argpase-ing).
Putting it all together
Of course, we don’t need to put the whole experimental setup in one big yaml file.
Actually, we do strive for modular configs, in the same fashion as we write our code modular.
Consequently, we would have separate files to configure model, data module, optimizer, and even a tensorboard logger.
Here is an outline of a template we use at LeapMind,it is inspired on ashleve’s theme:
.
├── configs
│ ├── callbacks
│ ├── datamodule
│ ├── experiment
│ ├── logger
│ ├── model
│ ├── optimizer
│ ├── scheduler
│ ├── trainer
│ ├── transforms
│ └── config.yaml
├── src
│ ├── architecture
│ ├── datasets
│ ├── pl_datamodules
│ ├── pl_models
│ └── utils
└── run.py
Generally, src includes all python scripts and configs has all yaml files.
The heart of the system is run.py – it’s hydra wrapper which glues both configs with src.
See
official tutorial
to learn how to do it (spoiler: it’s super easy, it’s just one decorator).
We recommend that initially configs contain the default configuration of a model, e.g a baseline.
Once confings for each single part of a project are defined, “aggregate” them in one master file, config.yaml:
defaults:
- trainer: superresnet50_trainer.yaml
- model: superresnet50.yaml
- optimizer: sgd.yaml
- datamodule: imagenet.yaml
- logger: tensorboard.yaml
Suppose you need to conduct an experiment with a new lr value.
First, create a new config under configs/experiments, then include the default configs, and finally override only those that you need:
defaults:
- override /trainer: superresnet50_trainer.yaml
- override /model: superresnet50.yaml
- override /optimizer: sgd.yaml
- override /datamodule: imagenet.yaml
- override /logger: tensorboard.yaml
datamodule:
data_dir: /data/imagenet-small
batch_size: 64
model:
num_classes: 200
learning_rate: 1e-3
In the development stage, feel free to modify the experiment configs. However, as soon as you made progress, freeze the configs and share it with your team, e.g by merging it to master branch on git, where it would remain untouched forever. If you want to add further changes, create a new config file!
Ready to boost your AI research?
Adding more layers of abstraction to the project might seem just cumbersome – but believe us – it’s really not! At LeapMind, hydra+lightning template was initially deployed on a small internal project, but eventually ended up being used company-wide, with many engineers using the same config files. It did save us many hours and it significantly boosted our workflow. Are you ready to boost your AI research now? Or maybe would you like to write some configs with us?
Written by Przemyslaw Joniak
Przemyslaw is a graduate student at The University of Tokyo. He appears at LeapMind a few days a week where he works on improving performance of our models.