2022年8月24日
Object DetectionにおけるAnchor Matchingについて - YOLOv2からATSSまで
概要
LeapMindの高橋です。現在Efficieraで提供する極小量子化された物体検出(Object Detection)モデルを開発しています。
物体検出モデルはComputer Visionの中でもメジャーな応用で注目度が高い一方、少し調べてみると「アンカーボックス」や「特徴マップピラミッド」など物体検出タスクに特有の概念がいくつも登場するため、とっつきにくい印象を持つかもしれません。
今回取り上げるAnchor Matchingはそんな物体検出モデルに特有な概念の一つで、ここ3年程で研究が特に発展してきたものです。Anchor Matchingについてそれほど日本語の記事はヒットしないのですが、これが分かれば物体検出モデルの全体像も把握しやすいのではないかと思い取り上げます。
物体検出モデルの概略
Anchor Matchingを導入するために、物体検出モデルについて簡単におさらいしましょう。
物体検出タスクは入力画像に含まれる物体の座標(localization)と種類(classification)を同時に推定し、後処理を行い検出結果としてバウンディングボックス:(center_x, center_y, width, height, score, class_id)のリストを出力します。
CNNによる典型的なODモデルのネットワーク構造は以下の3つのサブモジュールから構成されています。
- Backbone: ResNet50などで入力画像から特徴量を抽出する。
- Neck: Backboneから複数スケールの特徴マップを得て変換する。
- Head: Neckで得た各特徴マップごとに最終的なバウンディングボックスの出力に合わせて変換する。
図示すると次のようになります。
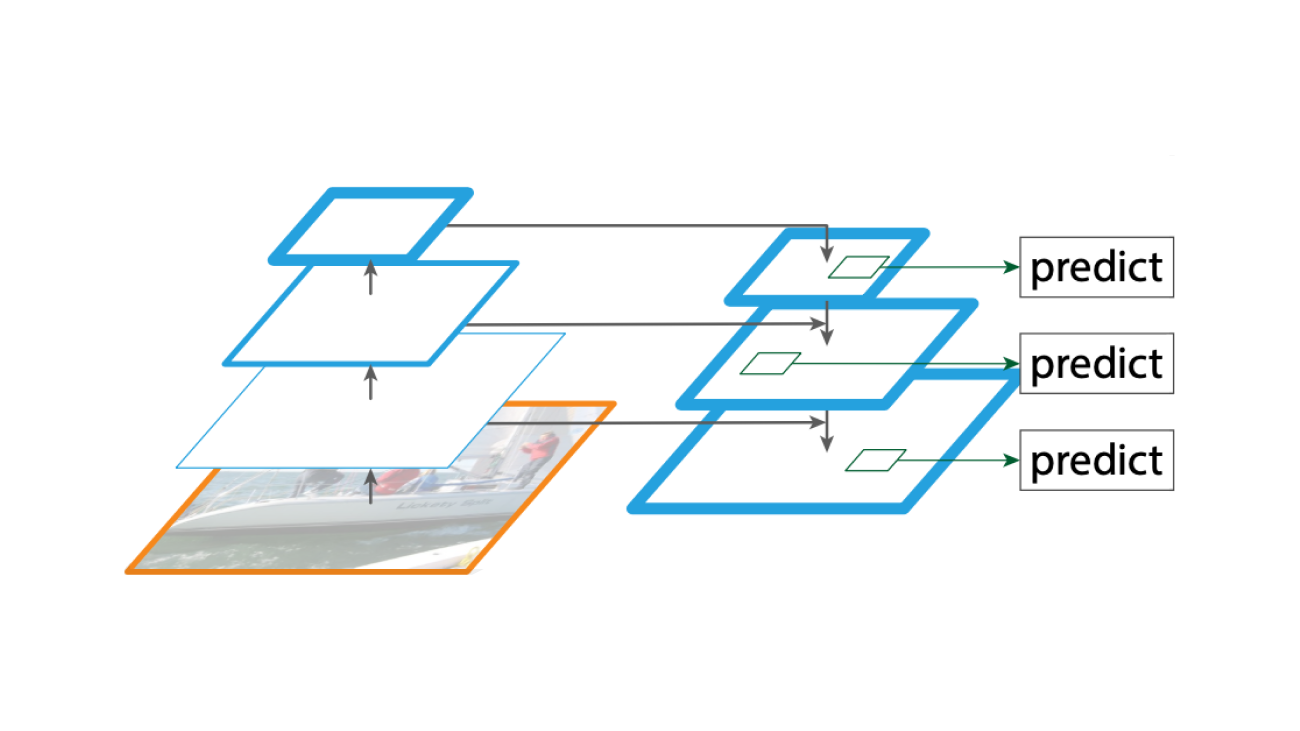
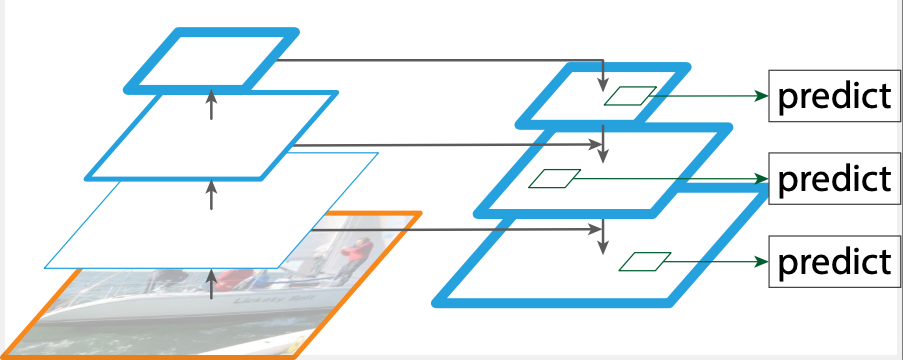 (図1. 文献2より加工して引用。Feature Pyramid Networks (FPNs)を採用した典型的なODモデルの例。)
(図1. 文献2より加工して引用。Feature Pyramid Networks (FPNs)を採用した典型的なODモデルの例。)
図1の左下オレンジに囲われた入力画像から上方向への処理がBackboneに相当します。上に行くことにダウンサンプリングされ空間スケールが粗い特徴量が得られます。次にNeckモジュールでは、Feature Pyramid Networks (FPNs)や類似したNeck構造を採用した場合、Backboneの各空間解像度の特徴量とNeckモジュールから得られた特徴量を組み合わせて、複数スケールからなる特徴マップピラミッドを構成します。最後にHeadモジュールでNeckから得られた特徴マップごとに最終的な出力をします。
Headから得られる最終的なネットワークの出力は、(batch_size, num_predictors, head_dim)となります。
ここでは、1つのバウンディングボックスに対応する出力のことをpredictorと呼び、その数をnum_predictorsとします。また、head_dimはclassificationとlocalizationに必要な情報、つまりCOCO datasetであればクラス数の80次元に加えてboxを表現する4次元が必要になります。 加えて、例えば以下で紹介するYOLOv2/v3の場合には、ネットワークの予測と正解間のIoUを推定するobjectivenessと呼ばれるパラメータが導入されているためhead_dim=85となります。
今回はAnchor Matchingを取り上げるため、以下Anchor-basedのモデルの場合のみを考えます。 Anchor-basedモデルでは各Predictorには対応するanchor boxが事前に定義されています。 図示したものが以下の図2になります。
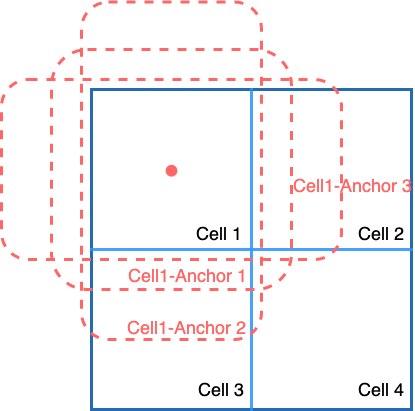
(図2.) 2x2のcell(特徴マップの一領域)に設定されたanchor boxesの例。
図2は簡単のために2x2のcell(特徴マップの一領域)があり、左上のcellに3つの縦長/横長/正方形のanchorを描画しました。実際にはすべてのcellに同様のanchorが設定されています。 実際のモデル、例えば以下のように、512x512の入力画像が与えられたとき、cellの数はP3:12288 P4:3072, P5: 768で合計16128個、それぞれに3つのanchor boxを割り当てるとnum_predictorsは16128*3=48384個になります。
image_width, image_height = 512, 512
num_anchors_per_cell = 3
p3_stride, p4_stride, p5_stride = 8, 16, 32
p3_num_predictor =
(image_width // p3_stride)
* (image_height // p3_stride)
* num_anchors_per_cell # 36864
p4_num_predictor =
(image_width // p4_stride)
* (image_height // p4_stride)
* num_anchors_per_cell # 9216
p5_num_predictor =
(image_width // p5_stride)
* (image_height // p5_stride)
* num_anchors_per_cell # 2304
num_predictors =
p3_num_predictor
+ p4_num_predictor
+ p5_num_predictor # 48384
どの物体とどのpredictorを対応させるかは自明ではありません。この問題をAnchor Matching、あるいはAnchor AssignmentやLabel Assignmentと呼びます。
Anchor Matching
Anchor Matchingのアルゴリズムは、与えられたバウンディングボックスのリストをモデルのpredictorに割り当てます。 各predictorは次の3つの状態のいずれかになります。
- positive: predictorに特定の物体が割り当てられている
- negative: predictorにいずれの物体も割り当てられていない
- ignore: predictorにいずれの物体も割り当てられないがnegativeとして学習しない
では具体的にどのようなアルゴリズムでマッチングを行うかみていきましょう。
YOLOv2/YOLOv3
YOLOv2/YOLOv3では、それぞれの物体に対して各feature mapごとにpredictorを最も適した1つだけ割り当てます。このアルゴリズムを我々はMax Matching / Max Matcherと呼んでいます。
具体的には次の2つの条件から最適な1つを選びます。
- cellに対応するピクセルに物体のcx, cyが含まれる
- 1で該当したcell内のanchorのうち物体とのIoUが最も高い
擬似コードに書き直すと次のようになります。
Max Matcherによる単一の物体に対する割り当て
class MaxMatcher(torch.nn.Module):
def __init__(self):
super().__init__()
self.strides = torch.Tensor(
[8, 16, 32], dtype=torch.long
)
self.anchors = torch.Tensor(
[[4.0, 4.0], [6.0, 3.0], [3.0, 6.0]],
dtype=torch.float,
)
self.num_anchors = 3
self.image_width, self.image_height = 512, 512
def forward(self, gt_label):
positive_predictors = []
cx, cy, width, height, class_id = gt_label
for stride in strides:
cell_in_row = (image_width // stride)
cell_index_x = cx // stride
cell_index_y = cy // stride
cell_index =
cell_index_x
+ cell_index_y * cell_in_row
anchor_gt_ious = compute_ious(
self.anchors, gt_label[:4]
)
anchor_index = torch.argmax(anchor_gt_ious)
predictor_index =
cell_index * self.num_anchors + anchor_index
positive_predictors.append(predictor_index)
return positive_predictors
cell_indexが条件1に対応し、 anchor_indexが条件2に対応します。
上の擬似コードでは省かれていますが、もしpositive_predictors以外が推論したバウンディングボックスと物体のIoUが設定した閾値以上だった場合は、そのpredictorはnegativeからignoreに割り当てなおします。
Max Matchingの欠点
YOLOv2/YOLOv3は偉大なモデルですが、Anchor Matchingの観点からみるといくつか欠点があります。
- 同じpredictorに複数のgt_boxが該当する場合に、学習時に1つのgt_boxしかないものとして学習される
- 各特徴マップごとに1つしか、正例/負例の不均衡(Imbalance Problems)が生じ学習が非効率的になる
ところで、YOLOv2/YOLOv3でなぜ暗黙のうちにMax Matchingが採用されているかというと、出力のcenter_x, center_yにsigmoid nonlinearityを適用しているため、表現できるboxの中心座標がcellの内部に限られているためです。以下で紹介するRetinaNetにはこのような制約がありません。
RetinaNet
RetinaNetは最も有名な物体検出モデルの一つです。論文の題が"Focal Loss for Dense Object Detection"とあるように、Classification部分にCross Entropy Lossから新規に提案したFocal Lossに変更して、YOLOv3などにあったobjectivenessパラメータを導入せずlocalization+classificationのみのlossで高精度のモデルを学習できることを明らかにしました。Focal Lossの詳細には立ち入りませんが、Cross Entropyと比べて正例/負例の不均衡を損失関数の重み付けを自動的に適切に行うことで、不均衡問題を緩和しています。
Anchor Matching部分はRetinaNet論文の主題ではないのですが、RetinaNetではYOLOv2/v3とは異なりanchor boxと物体間のIoUがそれぞれの閾値を基準にpredictorをpositive/ignore/negativeに割り当てるアルゴリズムを採用しています。閾値に基づいた割り当て方法なので、我々はこれをThresholdMatcherと呼んでいます。
Pythonの疑似コードで書いてみると次のようになります。
Threshold Matcherによる単一の物体に対する割り当て
class ThresholdMatcher(torch.nn.Module):
def __init__(
self,
positive_threshold=0.5,
negative_threshold=0.4
):
super().__init__()
self.positive_threshold=0.5
self.negative_threshold=0.4
self.strides = torch.Tensor(
[8, 16, 32], dtype=torch.long
)
self.anchors = torch.Tensor(
[[4.0, 4.0], [6.0, 3.0], [3.0, 6.0]],
dtype=torch.float
)
self.image_width, self.image_height = 512, 512
self.anchor_boxes = generate_anchor_boxes(
self.strides,
self.anchors,
self.image_width,
self.image_height
)
def forward(self, gt_label):
anchor_gt_ious = compute_ious(
self.anchor_boxes, gt_label
)
positive_predictors = torch.nonzero(
anchor_gt_ious >= self.positive_threshold
)
negative_predictors = torch.nonzero(
anchor_gt_ious <= self.negative_threshold
)
ignore_predictors = torch.nonzero(
torch.logical_and(
anchor_gt_ious < self.positive_threshold,
anchor_gt_ious > self.negative_threshold,
)
)
return positive_predictors, negative_predictors, ignore_predictors
実装は比較的簡単で、predictorのanchorをあらかじめ用意し、それとgtとの間のIoUを計算し条件式で分類します。
論文中ではこの点に対する言及はないのですが、1つの物体に対して各特徴マップごとに1つしか正例がないYOLOv3のMaxMatcherに比べて、正例/負例の不均衡がAnchor Matchingの面からみて緩和されている、という点は指摘できるでしょう。
Threshold Matcherの欠点
Threshold MatcherはMax Matcherと比較して、1つの物体に複数のpredictorを割り当てるため、不均衡問題は緩和されました。しかし、次の問題を指摘することができます。
- 大きい物体に対してはpositive predictorが多くなるが、小さい物体に対しては少なくなる。
- 閾値の設定が恣意的で精度への影響が大きい。
こうした問題をAnchor Matchingのアルゴリズムから解決したものがこれから紹介するATSSになります。
Adaptive Training Sample Selection (ATSS)
RetinaNetが公開されて以降、YOLO系とは異なった1段階モデルが数多く提案されるようになりました。そのうちの一つがFCOS: Fully Convolutional One-Stage Object Detectionというもので、1段階モデルとして既存のモデルから大幅な精度向上を達成しました。
今回取り上げる、Adaptive Training Sample Selection (適応的学習サンプル選択)論文ではRetinaNetとFCOSの精度の差異がどの要素によって生じているか実験から明らかにし、これがAnchor Matchingによって生じていると議論しました。
After applying those universal improvements, these are only two differences between the anchor-based RetinaNet (#A=1) and the anchor-free FCOS. One is about the classification sub-task in detection, i.e., the way to define positive and negative samples. Another one is about the regression sub-task, i.e., the regression starting from an anchor box or an anchor point.
意訳) これらの普遍的な改善手法を適用した結果、anchor-basedなRetinaNetとanchor-freeなFCOSには2つのみ違いがあります。1つが分類のサブタスクについてで、すなわちpositive sampleとnegative sampleをどのように定義するかです。もう1つが回帰のサブタスクで、回帰をanchor boxから行うかanchor pointから行うかという違いです。
...
According to these experiments conducted in a fair way, we indicate that the essential difference between one-stage anchor-based detectors and center-based anchorfree detectors is actually how to define positive and negative training samples, which is important for current object detection and deserves further study.
意訳) 公正に行われたこれらの実験によれば、1段階anchor-based検出器とcenter-based anchor-free検出器の違いはpositiiveとnegativeな学習サンプルをどのように適用するかで、これは現在の物体検出モデルにとって重要でさらなる研究が求められています。
論文ではここからアルゴリズムの導入に入ります。ATSSのアルゴリズムは必ずしも直感的に導かれたものではないですが、論文にも書かれている次の5つの条件を満たすという観点から天下り式に設計されたものです。
- anchor boxとgt boxの中央座標の距離を用いること
- anchor-gt間のIoUを用いること
- anchorの中央座標が物体の内側に含まれていること
- 物体の大きさによってpositive predictorの数が大きく影響されないこと
- ハイパーパラメタが少ないこと
実際のアルゴリズムは擬似コードでは簡潔に書きにくかったので、ここではアルゴリズムの手続きを書きました。
ATSSのアルゴリズム
すべてのanchor-gt間のIoUを計算する1と同様にanchor-gt間の中心座標の距離を計算するL個の特徴マップについて、それぞれのgtについて中心座標が最も近いK個のanchor boxを取得する3で得たK*L個のanchor boxのIoUを計算し、その平均+標準偏差を閾値とするIoUが閾値以上のanchor-gtペアについて、predictorに物体を割り当てる5でpositiveに割り当てられたもののうちanchor boxの中央が物体の内側に含まれていないものを省くpredictorに複数の物体が割り当てられた場合、IoUが最も高い物体を割り当てる。
登場するハイパーパラメタはKのみで論文中で最適値はK=9とされているもののK>=5であればモデルの精度に与える影響は軽微だと報告されています。
ResNet-101をbackboneとしたモデルでは、RetinaNetにATSSを導入することでMS COCO test-devでAPが39.1->43.6と4.5ptの大幅な上昇を達成したと記述されています。 推論時の計算量を増加させずに学習時のコストのみでこれだけ向上でき、これはモデル開発に大きなインパクトがあります。
終わりに
物体検出は非常にモデル設計の自由度が高いタスクです。Anchor Matchingはそのうちの一要素で、効率的にモデルを学習させるために重要な要素だとの認識が近年高まってきました。 直近ではProbabilistic Anchor Assignment (PAA)、YOLO-Fで導入されたUniform Matching、最適輸送問題として定式化したOptimal Transport Assignment (OTA)などが提案されており刺激的な領域です。また機会があれば、これらを紹介します。
ところでLeapMindでは物体検出モデルを始めとした、Computer Vision分野のモデル開発する機械学習エンジニアを絶賛募集中です!興味のある方は以下からぜひご応募ください!
文献
- Qiang Chen, Yingming Wang, Tong Yang, Xiangyu Zhang, Jian Cheng and Jian Sun. You Only Look One-level Feature. CVPR 2021.
- Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie. Feature Pyramid Networks for Object Detection. CVPR 2017.
- Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal Loss for Dense Object Detection. ICCV 2017.
- Joseph Redmon and Ali Farhadi. YOLO9000: Better, Faster, Stronger. CVPR 2017.
- Joseph Redmon and Ali Farhadi. YOLOv3: An Incremental Improvement. arXiv:1804.02767 2018.
- Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS: Fully Convolutional One-Stage Object Detection. ICCV 2019.
- Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and Stan Z. Li. Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection. CVPR 2020.