2022年6月20日
Pixel Embedding for Quantized Neural Networks
Hi, I'm Joel from LeapMind.
For this blog, I'll write a little about pixel embedding, which enables fast inference of the first layer of a quantized neural network. This has been very useful for me recently. If you work with quantized neural networks, maybe it can be useful for you too.
Background
Neural networks can perform various computer vision tasks, which receive images as input. For example, the noise reduction task. However, neural networks are typically heavy algorithms, which prohibit their use on small devices. Therefore, it is necessary to develop lightweight neural networks.
One way to achieve this is using extreme low bitwidth quantization. For example, 1, 2, or 4 bits are used for weights and activations of the neural network. By repeatedly chaining quantized convolution layers with quantization operators, inference of deep neural networks is greatly accelerated, and can even be run on small devices.
Problem setting
The quantized chain is cut at the first layer because the inputs are high bitwidth pixel values. Using the quantization operator on inputs doesn’t work well because it is not a featuremap. For example, when the input data is a black and white image, there is only one input channel (a single value per pixel). Quantizing single pixel values causes too much loss of information. Using non-quantized convolution for just the first layer is also not a good solution because it is slow relative to the other layers and will take up a significant fraction of the total inference time.
Pixel embedding concept
How to get a quantized featuremap from a high bitwidth input? The solution is pixel embedding, which was developed by our CTO Tokunaga-san. The inspiration is from word embedding of NLP. The fundamental idea is to use a lookup table that maps from a single high bitwidth pixel value to an array of quantized values, which is applied pixel-wise to the input image, resulting in a quantized featuremap.
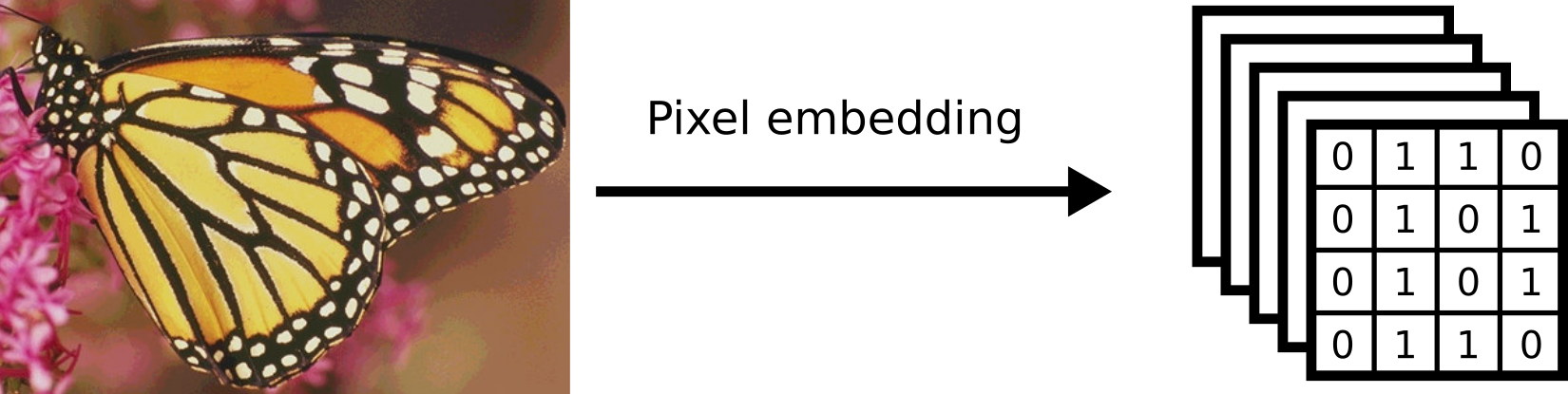
Figure 1: Pixel embedding maps the input image pixel-wise to a quantized featuremap, which can be used in quantized convolution. The butterfly photo is the test image “Monarch” from A color preserving image segmentation method.
Using this pixel embedding layer, the pixels of the image can be encoded in low bitwidth, allowing quantized convolution to be used in the first layer.
Pixel embedding initialization
The pixel embedding can be learned during the neural network training. However, in addition to learning, it is generally understood that having a good initialization of all layers is important for neural networks to get the best results.
Thermometer encoding
Thermometer encoding has been used in FracBNN and several other works as an effective way of encoding high bitwidth values into a binary array. The main idea is that a larger input value results in a binary array with a larger number of 1's.
This encoding can be imagined like a thermometer, the boundary between 0's and 1's is analogous to the height of the mercury in the tube. Input pixel value is analogous to temperature.
For quantized networks with bitwidths higher than 1, it's also possible to use a kind of thermometer encoding. When increasing the input pixel value, the array first becomes filled up with 1's. Then after that, the array starts to fill with 2's, then 3's and so on. Using thermometer encoding as the initialization for learned pixel embedding allows us to improve the results of the neural network.
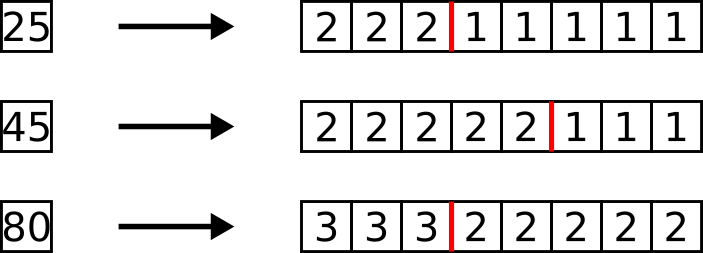
Figure 2: An example of pixel embedding using thermometer encoding with greater than 1bit quantization. The red line shows the boundary between values, illustrating the thermometer level. As the input value increases from 25 to 45, the red line moves to the right. As the input value further increases to 80, the red line begins again from the left side, with even higher values.
Why might this initialization work well?
The first thing I notice about the thermometer encoding is that input pixels with similar values result in similar quantized arrays. If the input pixel value is increased slowly, the boundary between ones and zeros in the quantized array will only move across by one element at a time.
This seems reasonable. If we imagine the extreme opposite, where similar input pixel values are mapped to very different quantized arrays, the neural network will have a more difficult task in learning how to process the image. If the input image pixels change by only 1 bit, we expect the neural network output to be very similar, but the embedded featuremap would be totally different!
Lets hypothesise a principle for high quality initialization of the embedding: “similar input pixel values map to similar quantized arrays”. Of course, we also need to avoid degenerate cases such as mapping all possible input pixel values to the same quantized array, because that would eliminate information.
Distance preserving mappings
If we were dealing with only real (floating precision) numbers, the ideal solution of “similar input pixel values map to similar real-valued arrays” is straightforward, so let’s start from there. Within the real numbers, the transforms that adhere to this principle exactly are called isometries, meaning the distances between inputs are equal to the distances between outputs. Further, due to Mazur-Ulam theorem, to be an isometry, the output array of real numbers would have to be an affine transform of the input pixel value. This theorem holds for quite a general definition of distance.
Let’s think of something similar for an output array of quantized values. Define the embedding like this: first do an affine transform on the input pixel, then apply a quantization operator. The resulting pixel embedding acts as something that roughly follows the principle “similar input pixels map to similar quantized arrays”.
Coming back to thermometer encoding, it can be formulated as a specific case of affine transform + quantizer. So it can be said to roughly follow the principle “similar input pixels map to similar quantized arrays”. Viewing thermometer encoding as an instance of affine transform + quantizer, I think the other important aspect is that the scale of inputs, scale of affine transformation, and scale of quantization operator must be well matched.