
Efficiera IP
他社AIアクセラレータとの比較において、性能(Power, Performance, Area)に圧倒的な差があり、実用的なAIモデルをエッジデバイス上で稼働させることが可能になっています。
優れた電力効率・面積効率を実現し、AI搭載製品の省電力化・低コスト化に貢献
AIを稼働させるためには、その膨大な計算量ゆえに、コンピュータ性能や消費電力などのハードウェア由来の影響が大きく、半導体性能が劇的に進化しない限り、エッジデバイス上で実用的にAIを稼働させることは困難です。
そういった中、当社では107.8TOPS/W*の演算能力を達成した、CNN(Convolutional Neural Network)の推論演算処理に特化した超低消費電力AIアクセラレータIPの開発を行い、AIの実用化に貢献しています。また、このIPを使ったTSMC 28nmと12nmでのSoC開発にも成功しています**。
ISO9001も取得、品質要求を満たすものになっています。
当社の強みである、量子化ビット数を1~2ビットまで最小化する「極小量子化」技術によって、推論処理の大部分を占めるコンボリューション(畳み込み演算)の電力効率と面積効率を最大化します。最先端の半導体製造プロセスや特別なセルライブラリを使用する必要がありません。
Efficieraを利用することで、スマートフォンやデジタルカメラなどの民生機器、自動車、建設機械などの産業機器、監視カメラ、放送機器をはじめとし、従来は技術的に困難であった、電力や放熱、コストに制約のある小型機械やロボットなど、様々なエッジデバイスへディープラーニング機能を組み込むことができます。
*TOPS/W: 1Wあたりのテラオペレーション/秒。
*Cadence社 Genus Synthesis Solutionを使った論理合成結果からの見積もり値。(動作周波数:533Mhz, プロセス:7nm, 2023年7月時点)
** https://www.nedo.go.jp/news/press/AA5_101526.html, https://www.nedo.go.jp/news/press/AA5_101614.html
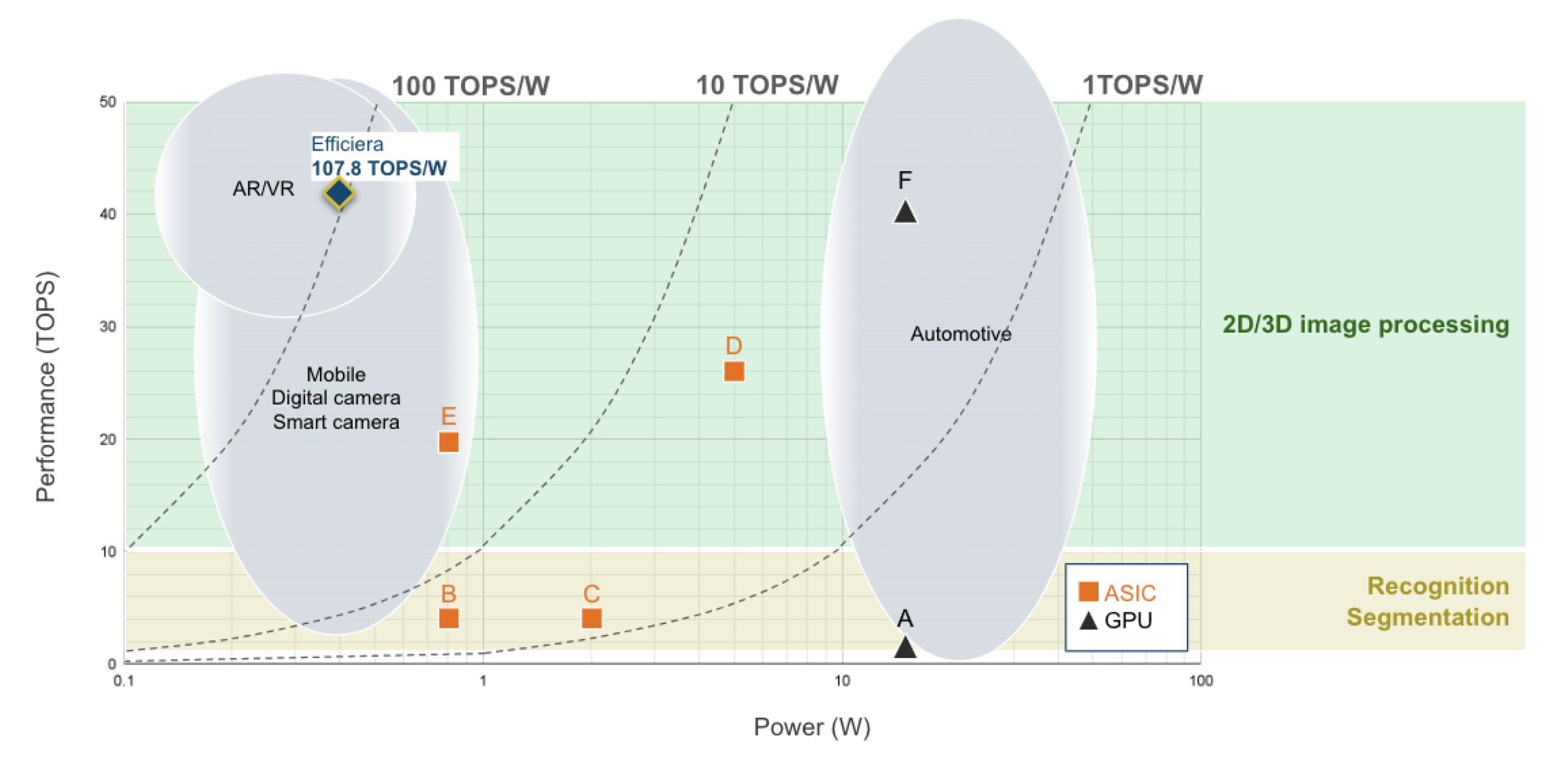
(AIタスクと要求性能)
FEATURES
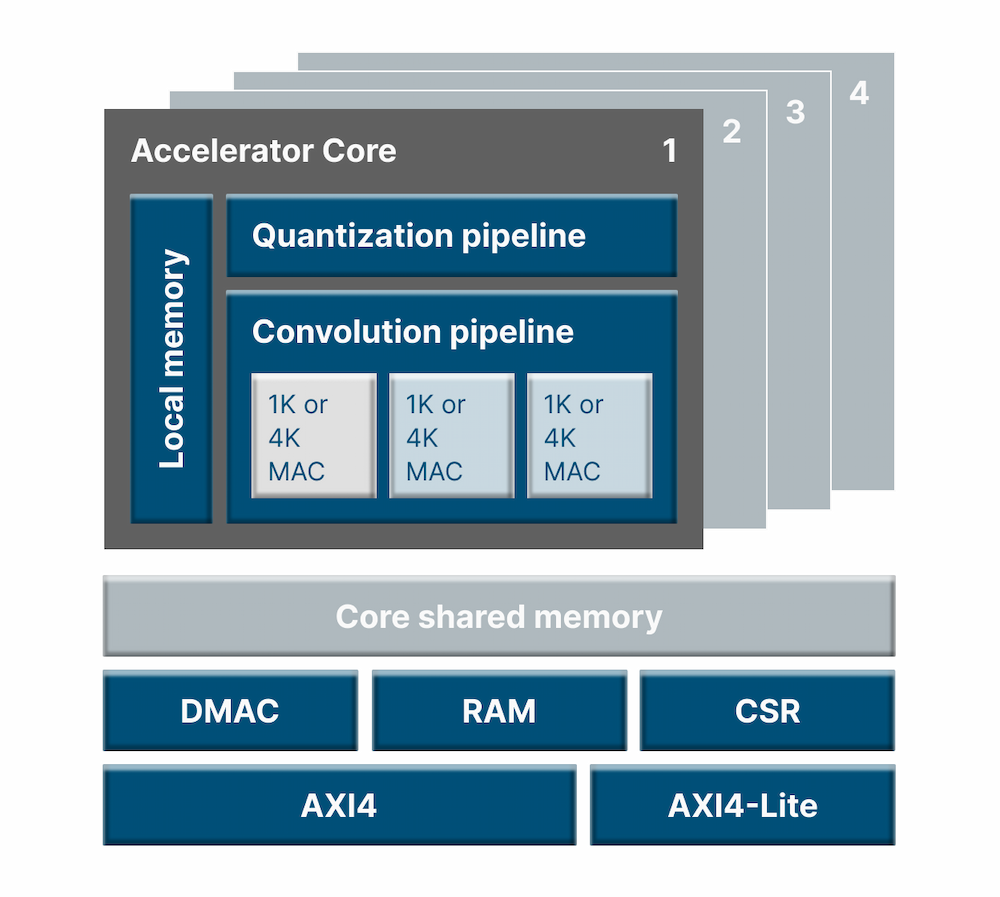

エッジデバイス上でAI処理を実現する優れた電力性能
LeapMindが独自で開発した、AIアクセラレータ「Efficiera」は、最大107.8TOPS/W*という電力性能を達成、リアルタイムでの高画質な画像/映像処理などもエッジデバイス上で処理が可能です。
*1Wあたりのテラオペレーション/秒
CNN(畳み込みニューラルネット)に特化した省面積半導体回路
畳み込みニューラルネットであれば、どのようなネットワークタスクでも動作することができるフレキシビリティと、最小構成で、0.245㎟と回路規模が非常に小さく、そのため、先端製造技術が不要、かつ消費電力を大幅に削減することが可能です。
回路規模は、ランダムロジック:1.88M gate、SRAM合計:10.7M bit、図のようにレイアウトし 1,086μm x 1,758μm のサイズとなります。
低消費電力の 6 track cell libraryを使用し、STVのcellのみの利用で533MHz動作を達成しました。また、動作周波数をさらに1066MHzまでUPすることが可能です。
Efficiera®️の性能スケーラビリティ
Efficieraは、合成可能なRTLとして提供されます。
回路構成選択による演算性能調整、および CPU占有率調整により、物体検出などの画像認識タスクだけでなく、画質改善などの画像処理タスクにおいても、リアルタイム(60FPS程度)に処理するために、必要なハードウェア性能レンジに対応することが可能です。
FUNCTIONS
ハードウェア機能
MACアレイの多重化 + マルチコア化により高い性能スケーラビリティを実現
畳み込み・量子化に加えてSkip connection(*1)とPixel Embedding(*2)をハードウェア実行することで高速化
*1 Skip connectionはレイヤー数の多いCNN(Convolutional Neural Network)でよく用いられる演算方法で、途中の複数層をN層分スキップして先の層へとつなげる迂回パスにより,離れた層間で順伝搬・逆伝搬を行えるようにする機構
*2 Pixel embeddingは、LeapMind独自の技術で自然言語処理で使われるワードエンベッディングと似たような手法を用い、各画素値に対してランダムな値を割り当て、ネットワークには画素値の代わりにベクトルを入力し、入力データの量子化を行う手法を用いることで、最初と最後の層を2bitに変換する技術
SoCへのインテグレーション
AMBA AXIインタフェース
外部とのインタフェースには引き続きAMBA AXIを採用、ブラックボックスとして見た場合のインタフェースは従来同様、既存の設計からの移行も容易
シングルクロックドメイン設計
動作周波数
12nmで1GHz。28nmで800MHz
適用範囲として、FPGA@125MHzで256GOP/s、12nmプロセス技術で104 TOP/sまで拡張可能。
PRODUCT LINEUP
Efficiera-B Configuration
画像認識アプリケーション用の超高効率IPです。主に、マルチチャネル入力による高レイテンシーが要求されるような厳しい環境や超高速の画像認識を、低消費電力、低メモリバンドで実行することが可能です。
Efficiera-E Configuration
画像処理アプリケーション用の超高効率IPです。主に、夜間撮影時のノイズ除去や、8Kへのアップスケーリング、ブレ補正などをリアルタイムかつ高精度で処理する必要があるようなシーンにおいて、従来は実現できなかったタスクを実行することが可能です。